Ingesting data from any sources with Databricks Data Intelligence Platform
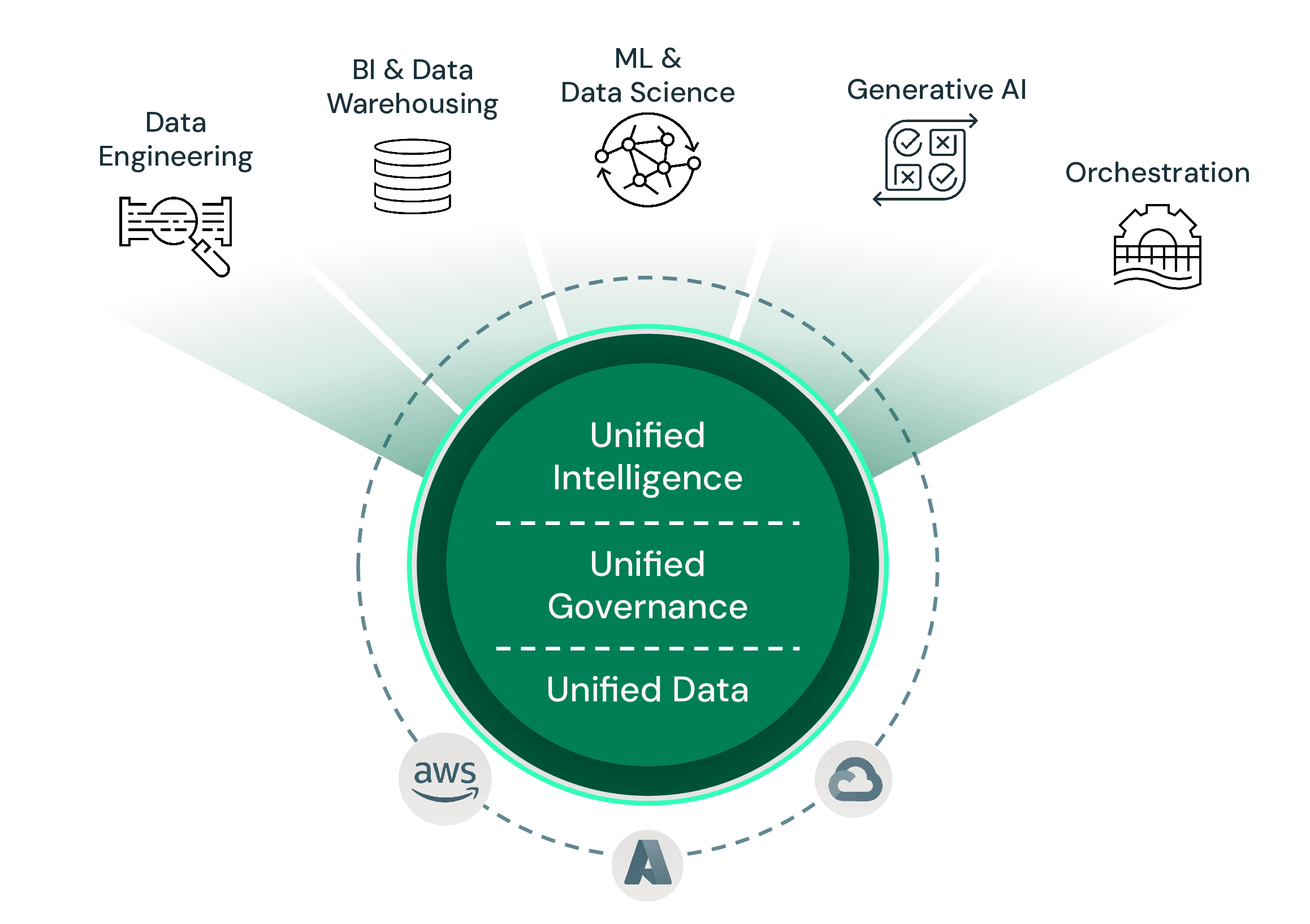
With the Databricks Data Intelligence Platform, you can effortlessly ingest data from virtually any source, unifying your entire data estate into a single, intelligent foundation. Whether it's batch, streaming, or change data capture (CDC), we provide robust, scalable, and easy-to-use tools to bring all your data into the Lakehouse.
Key capabilities include:
- **Universal Connectivity**: Native connectors for enterprise applications (Salesforce, ServiceNow, Workday), databases (SQL Server, Oracle, PostgreSQL), cloud object storage (S3, ADLS, GCS), messaging queues (Kafka, Kinesis, Pub/Sub), and custom APIs.
- **Automated & Incremental Ingestion**: Leverage powerful features like Auto Loader for efficient, incremental processing of new files as they arrive, and Lakeflow Connect for managed, serverless pipelines.
- **Real-time Ready**: Seamlessly ingest and process high-throughput streaming data for immediate insights, real-time dashboards, and instant decision-making.
- **Unified Governance**: Every ingested dataset is automatically governed by Unity Catalog, providing unified visibility, access control, lineage, and discovery across your entire data and AI assets.
- **Simplified Data Engineering**: Build and manage data ingestion pipelines with ease using declarative frameworks like Spark Declarative Pipelines (formely known as SDP), reducing complexity and accelerating time to value.
Break down data silos, accelerate your data and AI initiatives, and unlock the full potential of your data with the Databricks Data Intelligence Platform.
1/ Ingest from Business Applications with Lakeflow connect
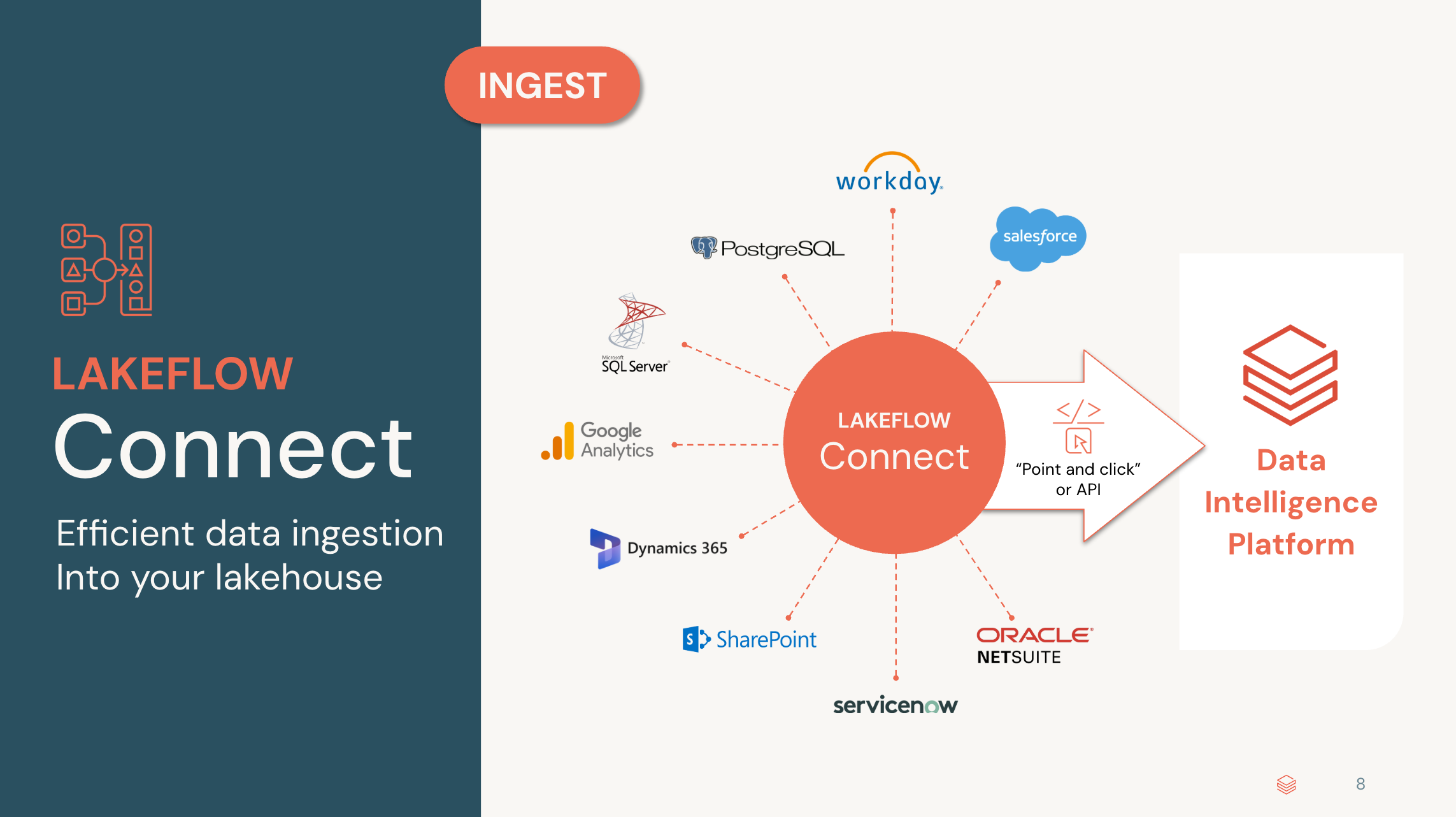
**Databricks Lakeflow Connect**
Lakeflow Connect is Databricks Lakeflow’s ingestion tool that makes it easy to bring data from many sources—including apps like Salesforce, Workday, and ServiceNow, plus databases, cloud storage, and streaming services—into your Databricks Lakehouse.
* Features an intuitive UI for fast setup
* Supports incremental and scalable, serverless ingestion
* Unifies governance with Unity Catalog for security and discoverability
Want to try Lakeflow Connect? Check these Product Tours:
[**Ingest from Salesforce:**](https://app.getreprise.com/launch/BXZjz8X/) Seamlessly integrates Salesforce CRM data (including custom objects and formula fields) with Databricks for analytics and AI.
[**Ingest Workday Reports:**](https://app.getreprise.com/launch/ryNY32X/) Quickly ingest and manage Workday data, as well as databases, cloud, and local files, with simple pipeline configuration.
2/ Read or ingest data in SQL with `read_file` and Spark Declarative PipelinesInstantly Access Any File with Databricks SQL's `read_files`
**Unlock your data's potential, no matter where it lives or what format it's in.**
The `read_files` function in Databricks SQL empowers you to directly query and analyze raw data files—from CSVs and JSONs to Parquet and more—stored in your cloud object storage or Unity Catalog volumes. Skip the complex setup and jump straight into insights.
**Simply point, query, and transform.** `read_files` intelligently infers schemas, handles diverse file types, and integrates seamlessly with streaming tables for real-time ingestion. It's the fast, flexible way to bring all your files into the Databricks Lakehouse, accelerating your journey from raw data to actionable intelligence.
Open [01-ingestion-with-sql-read_files]($./01-ingestion-with-sql-read_files)
3/ Ingest Files with Databricks Auto Loader
**Databricks Auto Loader** makes file ingestion simple and automatic. It incrementally detects and loads new data files from cloud storage into your Lakehouse—no manual setup required.
- **Fully automated streaming:** New data is picked up and processed instantly as it arrives.
- **Exactly-once data integrity:** Ensures files are processed just once, even after failures.
- **Supports schema evolution:** Automatically adapts as your data evolves.
- **Works with many file formats:** Handles JSON, CSV, Parquet, Avro, and more.
- **Seamless integration:** Built to work with Spark Declarative Pipelines and streaming pipelines.
Auto Loader lets you focus on getting insights from data—not on managing file arrivals or pipeline code.
Open [02-Auto-loader-schema-evolution-Ingestion]($./02-Auto-loader-schema-evolution-Ingestion)