Orchestrating and running dbt Pipelines on Databricks
In this demo, we'll show you how to run dbt pipelines with Databricks Lakehouse.
What's dbt
dbt is a transformation workflow that helps you get more work done while producing higher quality results. You can use dbt to modularize and centralize your analytics code.
dbt helps you write data transformations (typically in SQL) with templating capabilities. You can then easily test, explore and document your data transformations.
dbt + Databricks Lakehouse
Once your dbt pipeline is written, dbt will compile and generate SQL queries.
The SQL Transformation are then sent to your Databricks warehouse endpoint which will process the data available in your Lakehouse and update your data accordingly.
By leveraging Databricks SQL warehouse, you will get the best TCO for ETL, leveraging our engine (photon) for blazing fast transformation.
Ingesting data for C360 platfom
This demo replicate the Spark Declarative Pipelines ingestion pipeline available in the Lakehouse C360 platform demo `dbdemos.install('lakehouse-retail-c360')`
In this dbt pipeline, we'll work as a Data Engineer to build our c360 database. We'll consume and clean our raw data sources to prepare the tables required for our BI & ML workload.
We have 3 data sources sending new files in our blob storage (/demos/retail/churn/) and we want to incrementally load this data into our Datawarehousing tables:
- Customer profile data (name, age, adress etc)
- Orders history (what our customer bough over time)
- Streaming Events from our application (when was the last time customers used the application, typically a stream from a Kafka queue)
DBT as a Databricks Workflow task
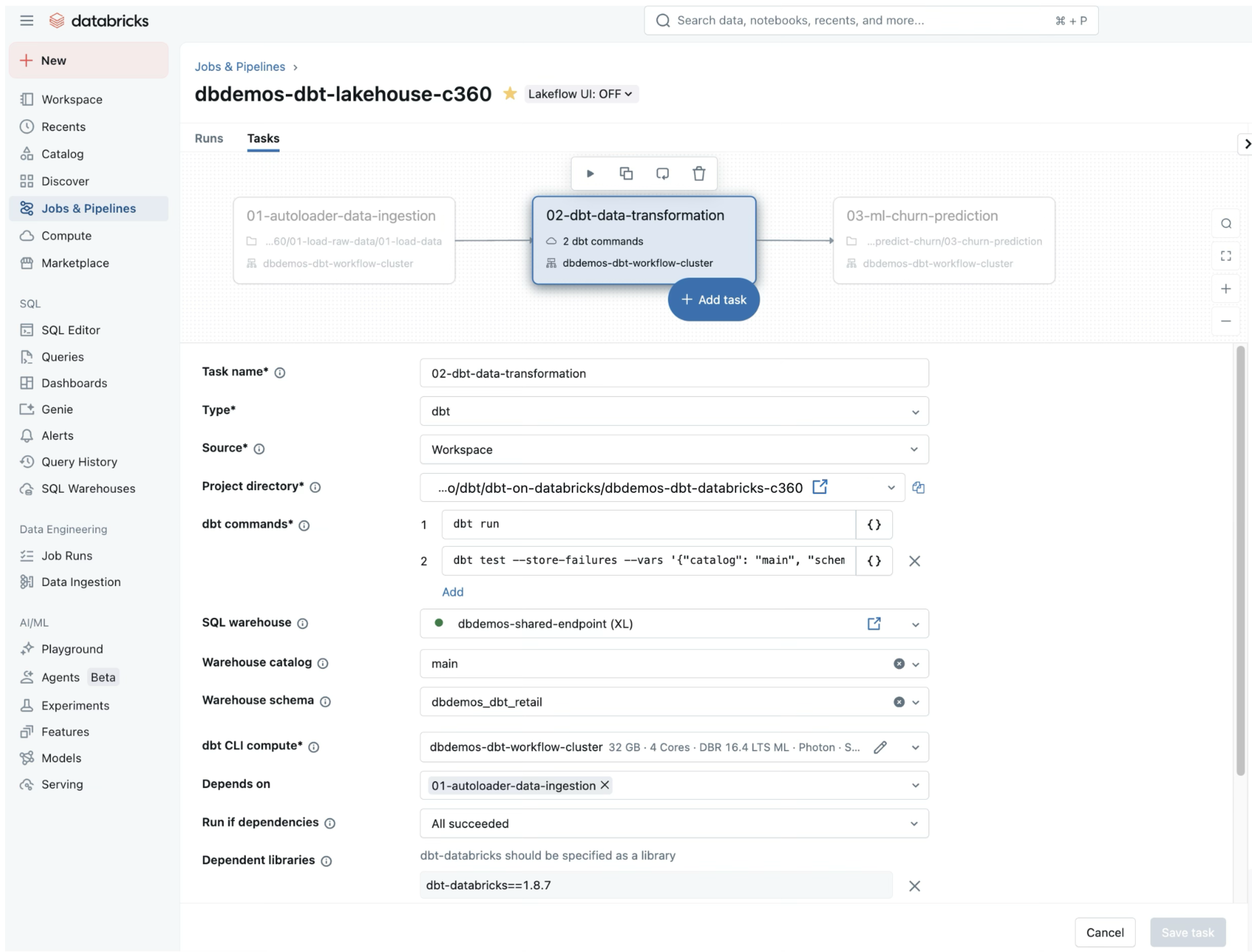
Databricks Workflow, the lakehouse orchestration tool, has a native integration with dbt.
You can easily add a new task launching a DBT pipeline within your ETL workflow.
To do so, simply select the "dbt" type in the task configuration and select which dbt CLI and command you want to run.
You can then select the SQL Warehouse you want to use to run the transformations.
Databricks will handle the rest.
Adding an ingestion step before dbt pipeline: "Extract" part of your ETL
DBT doesn't offer direct ways to ingest data from different sources. Typical ingestion source can be:
- files delivered on blob storage (S3/ADLS/GCS...)
- Message queue (kafka)
- External databases...
Databricks lakehouse solves this gap easily. You can leverage all our connectors, including partners (ex: Fivetran) to incrementally load new incoming data.
In this demo, our workflow will have 3 tasks:
- 01: task to incrementally extract files from a blob storage using Databricks Autoloader and save this data in our raw layer.
- 02: run the dbt pipeline to do the transformations, consuming the data from these raw tables
- 03: final task for the final operation (ex: ML predictions, or refreshing a dashboard)

Accessing the dbt pipeline & demo contentA workflow with all the steps have been created for you
Click here to access your Workflow job, it was setup and has been started when you installed your demo.
The dbt project has been loaded as part of your repos
Because dbt integration works with git repos, we loaded the [demo dbt repo](https://github.com/databricks-demos/dbt-databricks-c360) in your repo folder :
Click here to explore the dbt pipeline installed as a repository
The workflow has been setup to use this repo.
Going further with dbt
Setting up dbt Cloud + Databricks
dbt cloud helps team developping dbt pipelines faster. Once your pipeline is ready in dbt cloud, you can easily launch it in your Databricks Lakehouse with one of the best TCO.
The integration between dbt Cloud and Databricks is available out of the boxin the Partner Connect menu (bottom left of your screen).
You'll find all the required information to setup the connection between dbt Cloud and Databricks warehouse endpoints
In addition, you can watch this video going through the setup steps
A note on Spark Declarative Pipelines
Spark Declarative Pipelines is a declarative framework build by Databricks. It can also be used to build data pipeline within Databricks and provides among other:
- Ingestion capabilities to ingest data from any sources within your pipeline (no need for external step)
- Out of the box streaming capabilities for near-realtime inferences
- Incremental support: ingest and transform new data as they come
- Advanced capabilities (simple Change Data Capture, SCDT2 etc)
If you wish to know more about dlt, install the SDP demos: `dbdemos.install('pipeline-bike')`