Data Intelligence Platform for Financial Services - Serving the Underbanked population with the Databricks Lakehouse

What is The Databricks Data Intelligence Platform for Financial Services?
It's the only enterprise data platform that allows you to leverage all your data, from any source, on any workload to always offer more engaging customer experiences driven by real-time data, at the lowest cost. The Data Intelligence Platform is built on the following three pillars:
1. Simple
One single platform and governance/security layer for your data warehousing and AI to **accelerate innovation** and **reduce risks**. No need to stitch together multiple solutions with disparate governance and high complexity.
2. Open
Built on open source and open standards. You own your data and prevent vendor lock-in, with easy integration with external solution. Being open also lets you share your data with any external organization, regardless of their data stack/vendor.
3. Multicloud
Multicloud is one of the key strategic considerations for FS companies, 88% of single-cloud FS customers are adopting a multi-cloud architecture (reference). Multicloud architecture, however can be expensive and difficult to build. The Lakehouse provides one consistent data platform across clouds and gives companies the ability to process your data where your need.

Raising Interest Rates - an opportunity or a threat?
The current raising interest rates can be both a great opportunity for retail banks and other FS organizations to increase their revenues from their credit instruments (such as loans, mortgages, and credit cards) but also a risk for larger losses as customers might end up unable to repay credits with higher rates. In the current market conditions, FS companies need better credit scoring and decisioning models and approaches. Such models, however, are very difficult to achieve as financial information might be insufficient or siloed.
In its essence, good credit decisioning is a massive data curation exercise.
DEMO: upsell your underbanked customers and reduce your risk through better credit scoring models
In this demo, we'll step in the shoes of a retail bank trying to utilize the current interest rates hike and enhance it's bottom line performance (both increasing revenue and decreasing costs).
The business has determined that the bank's focus is at improving the credit evaluation of current and potential credit customers. We're asked to:
* Identify customers who do not currently have a credit instrument but would have a good credit score (upselling the underbanked clients to increase revenue),
* Evaluate the possibility of default of the bank's current credit holders (reducing risk thereby reducing loss).
What we will build
To do so, we'll build an end-to-end solution with the Lakehouse. To be able to properly analyze and predict creditworthiness, we need information coming from different external and internal systems: credit bureau data, internal banking data (such as accounts, KYC, collections, applications, and relationship), real-time fund and credit card transactions, as well as partner data (in this case, telecom data) to enhance our internal information.
At a high level, we will implement the following flow:
1
Ingest all the various sources of data and create our credit decisioning database (unification of data) 2
Secure data and grant read access to the Data Analyst and Data Science teams, including row- and column-level filtering, PII data masking, and others (data security and control)3
Use the Databricks unified data lineage to understand how your data flows and is used in your organisation4
Run BI queries and EDA to analyze existing credit risk5
Build ML model to predict credit worthiness of underbanked customers, evaluate the risk of current debt-holders, and deploy ML models for real-time serving in order to enable Buy Now, Pay Later use cases6
Visualise your business models along with all actionable insights coming from machine learning7
Provide an easy and simple way to securely share these insights to non-data users, such as bank tellers, call center agents, or credit agents (data democratization)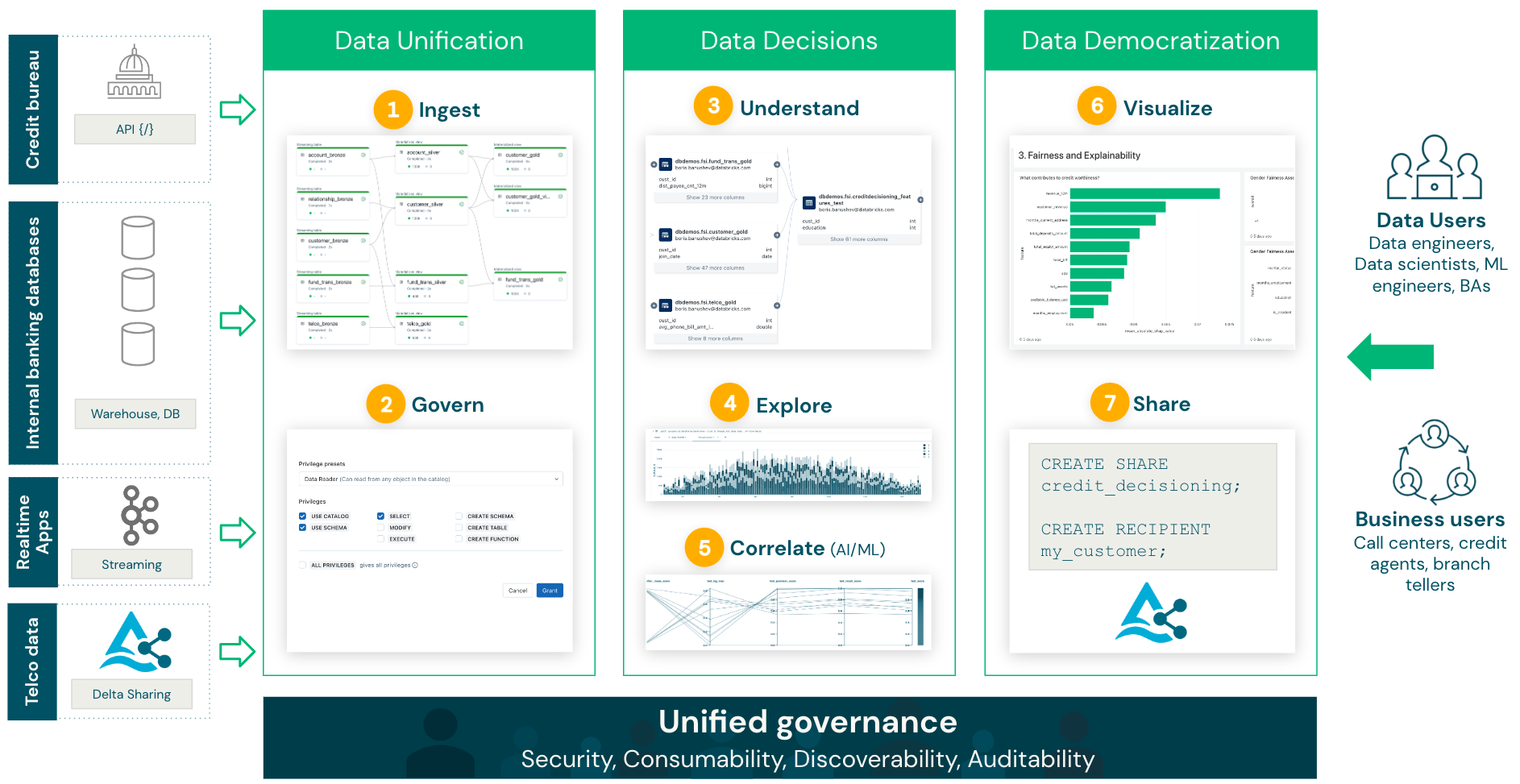
Setting the Foundations in Financial Services
Governance is top of mind for every financial services institution today. This focus is largely due to multi-cloud trends, proliferation of sensitive data from digital data sources, and the explosion of data products and data sharing needs. Our governance solution provides 3 key capabilities that we will focus on:
1. **Data Security**: Databricks has [Enhanced Security and Compliance](https://www.databricks.com/trust/protect-your-data-with-enhanced-security-and-compliance) to help any FSI monitor and keep their platform secure. Databricks also has built-in encryption functions, customer-managed keys, and Private Link across clouds to provide advanced security expected by FSIs.
2. **Lineage and Discoverability**: When handling sensitive data, understanding lineage for audit and compliance is critical. Discoverability means any downstream consumer has insight into trusted data.
3. **Sharing data with non-data users**: Data Sharing has arisen from needs to access data without copying vast amounts of data. As the Financial Services industry moves toward multi-cloud and develops products in open banking, consumer lending and fraud, sharing data with open standards provides the right foundation to avoid cloud lock-in and help FSIs democratize data.
1: Ingesting data & building our FS Lakehouse Database
First, we need to ingest and transform customer, credit, and payments data sources with the [Spark Declarative Pipelines SQL Pipeline notebook]($./01-Data-Ingestion/01-SDP-Internal-Banking-Data-SQL). This will create a SDP Pipeline running in batch or streaming, and saving our data within Unity Catalog as Delta tables.
2: Governance
Now that our data has been ingested, we can explore the catalogs and schemas created using the [Data Explorer](/explore/data/dbdemos/fsi_credit_decisioning).
To leverage our data assets across the entire organization, we need:
* Fine grained ACLs for our Analysts & Data Scientists teams
* Lineage between all our data assets
* real-time PII data encryption
* Audit logs
* Data Sharing with external organization
Discover how to do that with the [02-Data-Governance-credit-decisioning]($./02-Data-Governance/02-Data-Governance-credit-decisioning) notebook.
3: ML - Building a credit scoring model to predict payment defaults, reduce loss, and upsell
Now that our data is ready and secured, let's create a model to predict the risk and potential default of current creditholders and potential new customers.
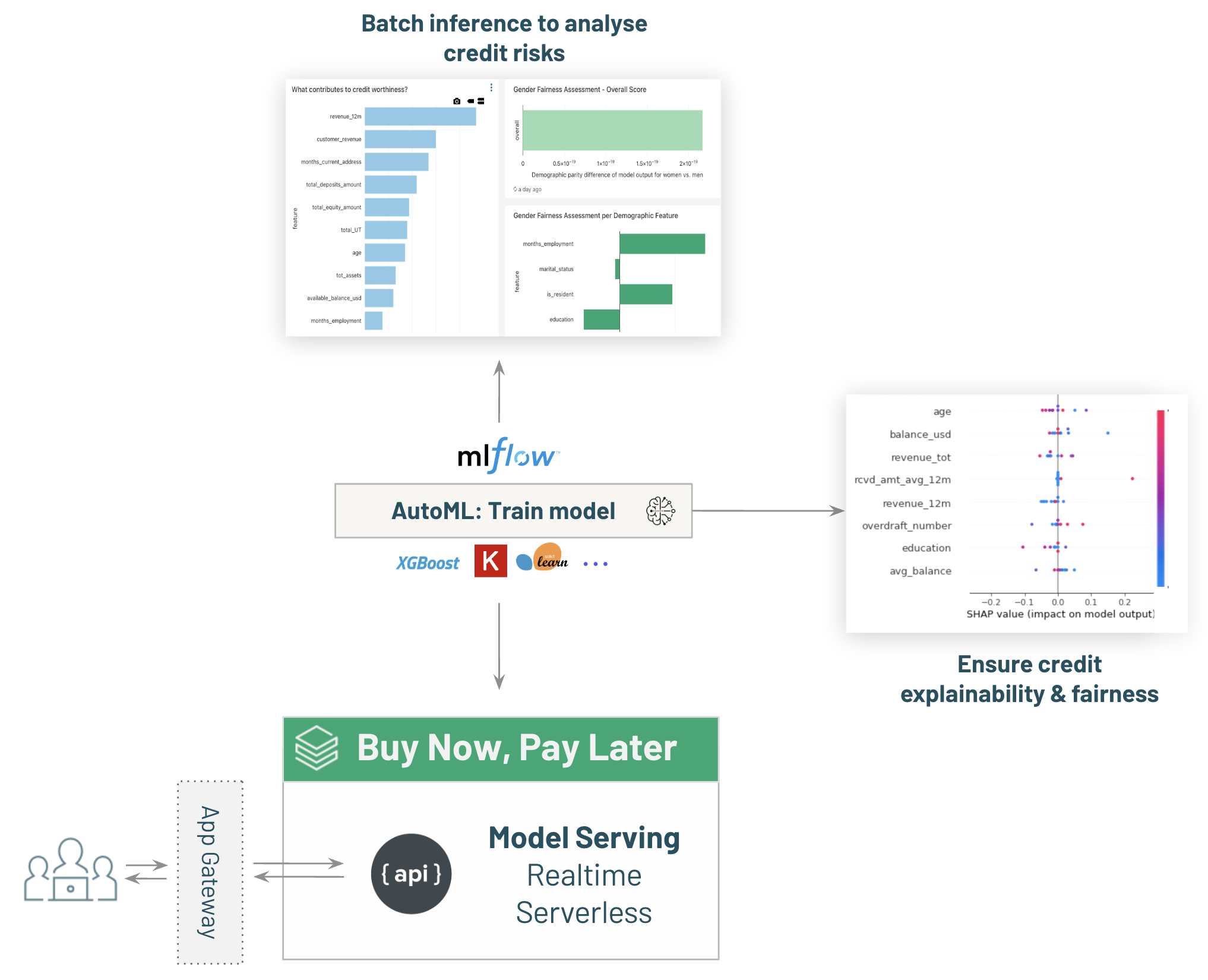
To do that, we'll leverage the data previously ingested, analyze, and save the features set within Databricks feature store.
Databricks AutoML will then accelerate our ML journey by creating state of the art Notebooks that we'll use to deploy our model in production within MLFlow Model registry.
Once our is model ready, we'll leverage it to:
Score, analyze, and target our existing customer database
Once our model is created and deployed in production within Databricks Model registry, we can use it to run batch inference.
The model outcome will be available for our Analysts to implement new use cases, such as upsell or risk exposure analysis (see below for more details).
Deploy our model for Real time model serving, allowing Buy Now, Pay Later (BNPL)
Leveraging Databricks Lakehouse, we can deploy our model to provide real-time serving over REST API.
This will allow us to give instant results on credit requests, allowing customers to automatically open a new credit while reducing payment default risks.
Ensure model Explainability and Fairness
An important part of every regulated industry use case is the ability to explain the decisions taken through data and AI; and to also be able to evaluate the fairness of the model and identify whether it disadvantages certain people or groups of people.
The demo shows how to add explainability and fairness to the final dashboard:
1. Feature importance and SHAP ratios charts are added to provide an overall understanding as to what are the drivers and root causes behind credit worthiness and defaults, so the bank can take appropriate measures,
2. Detailed fairness like gender fairness score and a breakdown of different demographic features, such as education, marital status, and residency.
Machine Learning next steps:
* [03.1-Feature-Engineering-credit-decisioning]($./03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning): Open the first notebook to analyze our data and start building our model leveraging Databricks Feature Store and AutoML.
* [03.2-AutoML-credit-decisioning]($./03-Data-Science-ML/03.2-AutoML-credit-decisioning): Leverage AutoML to accelerate your model creation.
* [03.3-Batch-Scoring-credit-decisioning]($./03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning): score our entire dataset and save the result as a new delta table for downstream usage.
* [03.4-model-serving-BNPL-credit-decisioning]($./03-Data-Science-ML/03.4-model-serving-BNPL-credit-decisioning): leverage Databricks Serverless model serving to deploy a Buy Now Pay Later offers (including AB testing).
* [03.5-Explainability-and-Fairness-credit-decisioning]($./03-Data-Science-ML/03.5-Explainability-and-Fairness-credit-decisioning): Explain your model and review fairness.
4: Building SQL Dashboard Leveraging our model to deliver real business value

Target customers without credit and suggest new offers to the less exposed
Using the model we built, we can score current and new customers to offer credit instruments (such as credit cards, loans, and mortgages).
We'll use our model outcome to only upsell customer filter our customers and build a dashboard including all this information:
1. Evaluates the credit worthiness of individuals without financial history,
2. Estimates the ROI and revenue from upselling current customers who do not have credit instruments,
3. Provides explainability on an individual level, making it easier to create targeted offers to each customer.
Such dashboards can be very easily built in the Databricks Lakehouse and used by marketing teams and credit departments to contact upsell prospects (including a detailed reason for creditworthiness).
Score our existing credit database to analyze our customers
1. Predicts the current credit owners likely to default on their credit card or loan and the "Loss given default",
2. Gives an overview of the current risk profile, the number of defaulted customers, and the overall loss,
3. A breakdown of loss per different credit instruments, such as credit cards, loans, and mortgages.
Open the [04-BI-Data-Warehousing-credit-decisioning]($./04-BI-Data-Warehousing/04-BI-Data-Warehousing-credit-decisioning) notebook to know more about Databricks SQL Warehouse.
Directly open the final dashboard depicting the business outcomes of building the credit decisioning on the Databricks Lakehouse, including:
- Upselling and serving the underbanked customers,
- Reducing risk and predicting default and potential losses,
- Turning the data into actionable and explainable insights.
5: Workflow orchestration
Now that all our lakehouse pipeline is working, let's review how we can leverage Databricks Workflows to orchestrate our tasks and link them together: [06-Workflow-Orchestration-credit-decisioning]($./06-Workflow-Orchestration/06-Workflow-Orchestration-credit-decisioning).