Data Intelligence Platform for HLS - Patient Cohorts and re-admission
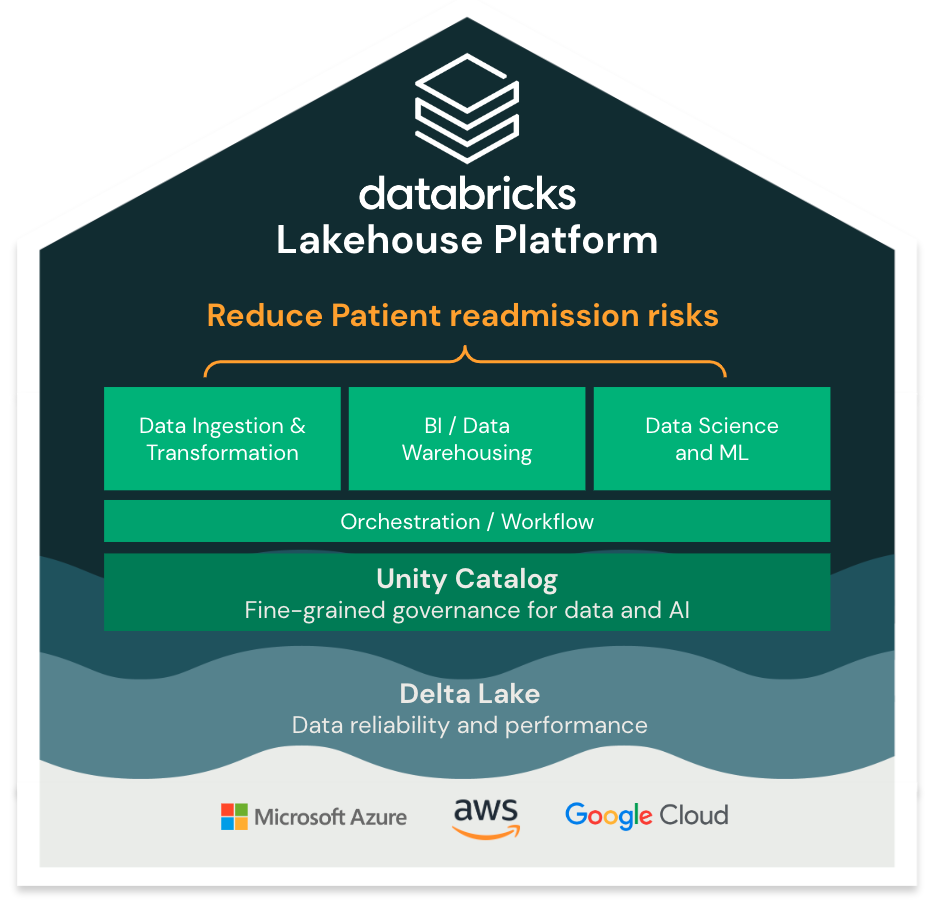
What is The Data Intelligence Platform for HLS?
It's the only enterprise data platform that allows you to leverage all your data, from any source, on any workload at the lowest cost.
1. Simple
One single platform and governance/security layer for your data warehousing and AI to **accelerate innovation** and **reduce risks**. No need to stitch together multiple solutions with disparate governance and high complexity.
2. Open
Open source in healthcare presents a pivotal opportunity for data ownership, prevention of vendor lock-in, and seamless integration with external solutions. By leveraging open standards, healthcare organizations gain the flexibility to share data with any external entity. This promotes interoperability, advances collaboration, and enables comprehensive data analysis, driving improved patient outcomes and operational efficiency.
3. Multicloud
Adoption of a multi-cloud strategy in healthcare organizations is inevitable and integral to competitive success, delivering cost reduction, flexibility, and improved remote services.

DEMO: Predicting patient re-admissions
Accurate prediction of patient readmissions holds immense value for hospitals and insurance companies:
***Higher Quality Care:***
It enables hospitals to enhance patient care by proactively identifying individuals at a higher risk of readmission. By identifying these patients early on, healthcare providers can implement targeted interventions, such as personalized discharge plans, medication adherence support, or follow-up appointments, to mitigate the likelihood of readmissions.
This approach not only improves patient outcomes but also reduces the burden on healthcare facilities and optimizes resource allocation.
***Cost Optimization***
Precise readmission prediction plays a pivotal role in cost containment for both hospitals and insurance groups. Hospital readmissions contribute significantly to healthcare expenditures, and accurate prediction can help identify patterns and risk factors associated with costly readmission cases. Developpigng proactive approach not only reduces healthcare costs but also promotes financial sustainability for hospitals and insurance providers.
Databricks offers hospitals and insurance companies unique capabilities to predict readmissions and drive value. Databricks' holistic approach empowers healthcare organizations to leverage data effectively and achieve accurate readmission predictions while saving time and resources.
What we will build
To predict patient re-admissions, we'll build an end-to-end solution with the Lakehouse, leveraging data from external and internal systems: patient demographics, logitudinal health records (past visits, conditions, allergies, etc), and real-time patient admission, discharge, transofrm (ADT) information...
At a high level, we will implement the following flow:
1
Ingest all the various sources of data and create our longitudinal health records database (based on OMOP CDM) (unification of data) 2
Secure data and grant read access to the Data Analyst and Data Science teams, including row- and column-level filtering, PHI data masking, and others (data security and control). Use the Databricks unified data lineage to understand how your data flows and is used in your organisation4
Run BI queries and EDA to analyze population-level trends5
Build ML model to predict readmission risk and deploy ML models for real-time serving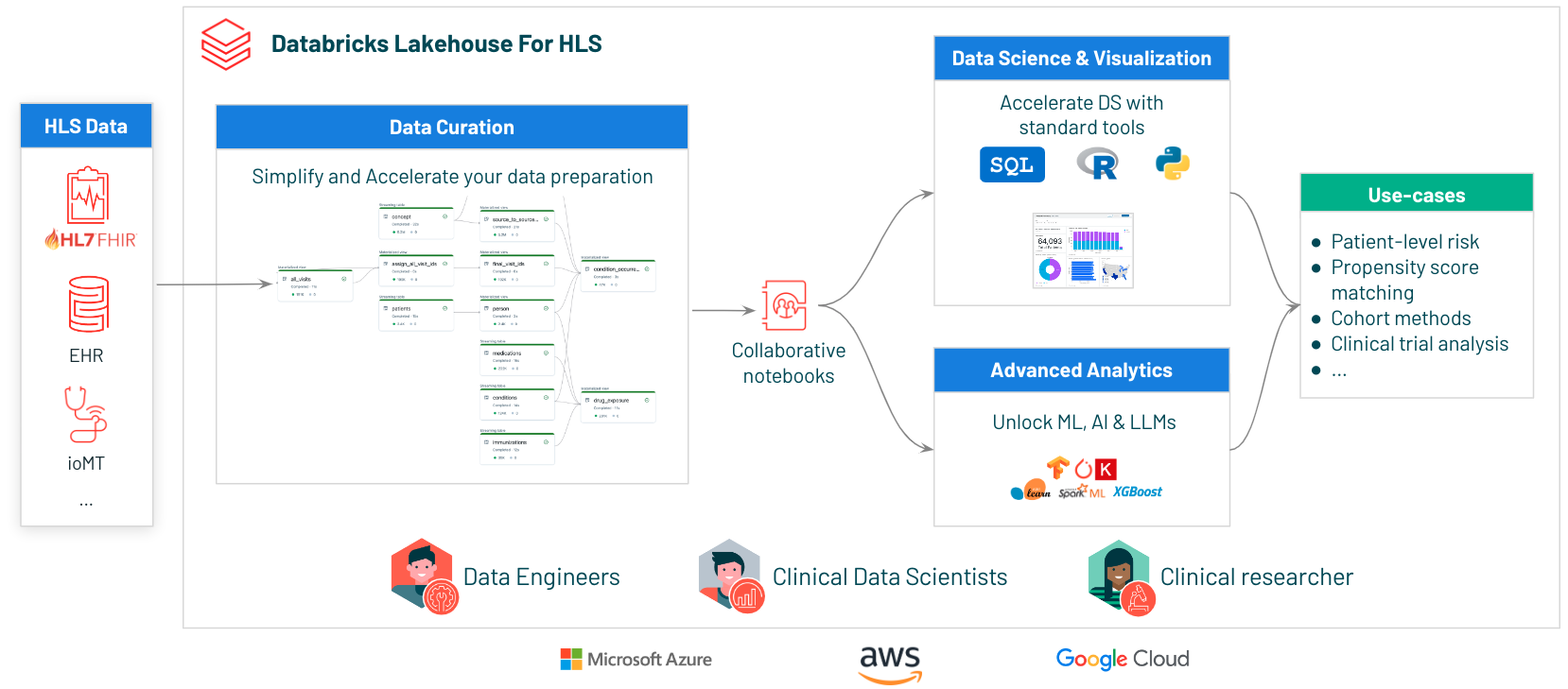
1/ Ingesting and preparing the data (Data Engineering)
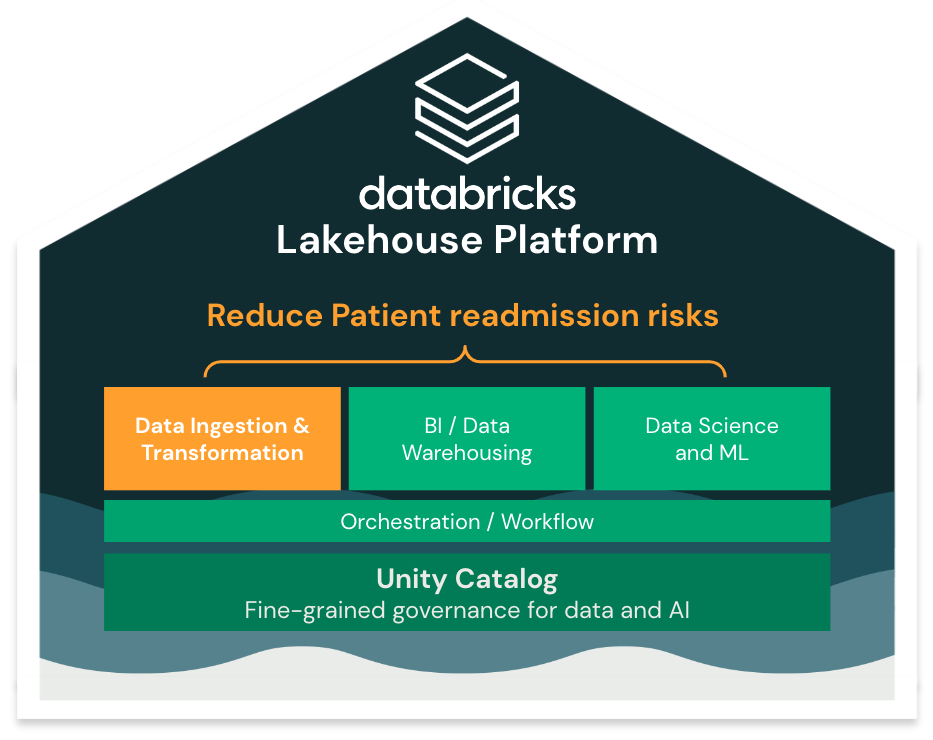
Our first step is to ingest and clean the raw data we received so that our Data Analyst team can start running analysis on top of it.
Delta Lake
All the tables we'll create in the Lakehouse will be stored as Delta Lake table. [Delta Lake](https://delta.io) is an open storage framework for reliability and performance.
It provides many functionalities *(ACID Transaction, DELETE/UPDATE/MERGE, Clone zero copy, Change data Capture...)*
For more details on Delta Lake, run `dbdemos.install('delta-lake')`
Simplify ingestion with Spark Declarative Pipelines (SDP)
Databricks simplifies data ingestion and transformation with Spark Declarative Pipelines by allowing SQL users to create advanced pipelines, in batch or streaming. The engine will simplify pipeline deployment and testing and reduce operational complexity, so that you can focus on your business transformation and ensure data quality.
Open the HLS patient readmission Spark Declarative Pipelines pipeline or the [SQL notebook]($./01-Data-Ingestion/01.1-SDP-patient-readmission-SQL) *(python SDP notebook alternative coming soon).*
For more details on SDP: `dbdemos.install('pipeline-bike')` or `dbdemos.install('declarative-pipeline-cdc')`
2/ Securing data & governance (Unity Catalog)
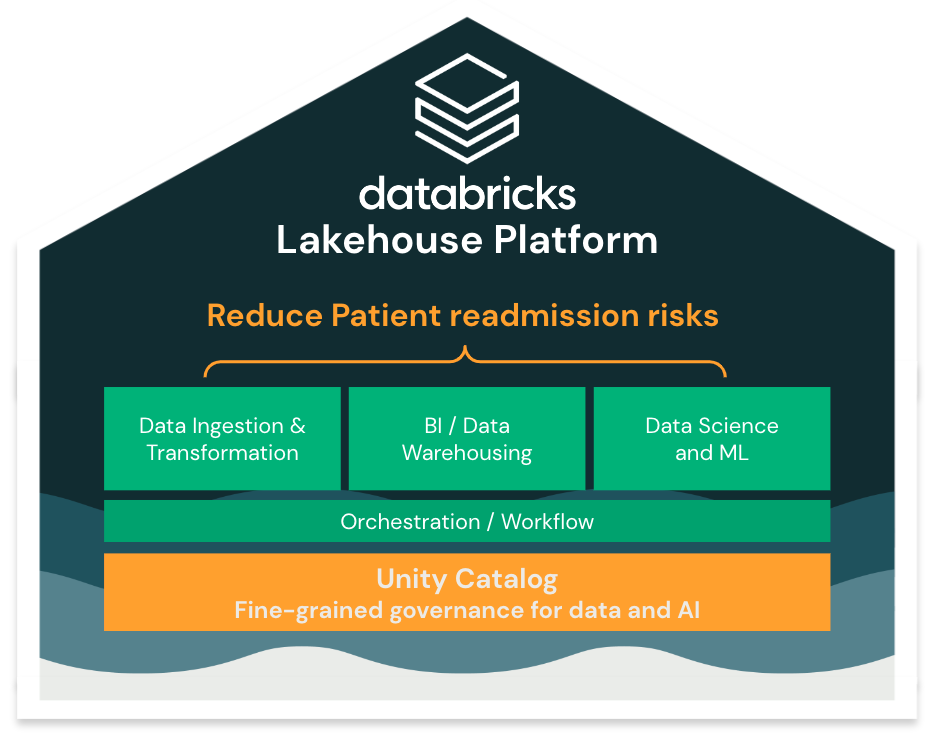
Now that our data has been ingested, we can explore the catalogs and schemas created using the [Data Explorer](/explore/data/dbdemos/fsi_credit_decisioning).
To leverage our data assets across the entire organization, we need:
* Fine grained ACLs for our Analysts & Data Scientists teams
* Lineage between all our data assets
* real-time PII data encryption
* Audit logs
* Data Sharing with external organization
Open the [Unity Catalog notebook]($./02-Data-governance/02-Data-Governance-patient-readmission) to see how to setup ACL and explore lineage with the Data Explorer.
3/ Analyse patient and build cohorts dashboards (BI / Data warehousing / SQL)

Our datasets are now properly ingested, secured, with a high quality and easily discoverable within our organization.
Data Analysts are now ready to run adhoc analysis, building custom cohort on top of the existing data. In addition, Databricks provides BI interactive queries, with low latencies & high througput, including Serverless Datawarehouses providing instant stop & start.
Open the [Clinical Data Analysis notebook]($./03-Data-Analysis-BI-Warehousing/03-Data-Analysis-BI-Warehousing-patient-readmission) to start building your cohorts or directly open the Patient analysis dashboard
4/ Predict readmission risk with Data Science & Auto-ML
Being able to run analysis on our past data already gave us a lot of insight to drive understand over-all patient risk factors.
However, knowing re-admission risk in the past isn't enough. We now need to take it to the next level and build a predictive model to forecast risk.
This is where the Lakehouse value comes in. Within the same platform, anyone can start building ML model to run such analysis, including low code solution with AutoML.
Machine Learning next steps:
* [04.1-Feature-Engineering-patient-readmission]($./04-Data-Science-ML/04.1-Feature-Engineering-patient-readmission): Open the first notebook to analyze our data and start building our model leveraging Databricks AutoML.
* [04.2-AutoML-patient-admission-risk]($./04-Data-Science-ML/04.2-AutoML-patient-admission-risk): Leverage AutoML to accelerate your model creation.
* [04.3-Batch-Scoring-patient-readmission]($./04-Data-Science-ML/04.3-Batch-Scoring-patient-readmission): score our entire dataset and save the result as a new delta table for downstream usage.
* [04.4-Model-Serving-patient-readmission]($./04-Data-Science-ML/04.4-Model-Serving-patient-readmission): leverage Databricks Serverless model serving to deploy instant risk evaluation and personalization.
* [04.5-Explainability-patient-readmission]($./04-Data-Science-ML/04.5-Explainability-patient-readmission): Explain your model and provide specialized care.
Extra:
* [04.6-EXTRA-Feature-Store-ML-patient-readmission]($./04-Data-Science-ML/04.6-EXTRA-Feature-Store-ML-patient-readmission): Discover how to leverage Databricks Feature Store to create and share Feature tables with your entire organization.
5: Workflow orchestration for patient readmission
Now that all our lakehouse pipeline is working, we need to orchestrate all the different steps to deploy a production-grade pipeline. Typical steps involve:
- Incrementally consume all new data every X hours (or in realtime)
- Refresh our dashboards
- Retrain and re-deploy our models
Databricks lakehouse provides Workflow, a complete orchestrator to build your pipeline, supporting taks with any kind of transformation.
Open the [05-Workflow-Orchestration-patient-readmission notebook]($./05-Workflow-Orchestration/05-Workflow-Orchestration-patient-readmission) to review how we can leverage Databricks Workflows to orchestrate our tasks and link them together.
Conclusion
In this demo, we reviewed how to build a complete data pipeline, from ingestion up to advanced Clinical Data Analyzis.
Databricks Lakehouse is uniquely position to cover all your data use-case as a single, unify platform.
This simplify your Data Processes and let you accelerate and focus on your core Health Care business, increasing health care quality, reducing patient readmission risk and unlocking all sort of use-cases: cohort analyzis, clinical trial analysis and modeling, RWE and more.