DSPy + MLflow for Automatically Optimizing LLM Programs#
DSPy (Declarative Self-improving Python) is an open-source framework that enables users to write Python code, rather than prompts, to build and direct LLMs. DSPy includes tools for directing the bahavior of LLMs, automatically optimize prompts and weights, and evaluate the performance of AI systems.
MLflow’s native integration with DSPy allows you to track and visualize the performance of your AI systems and to log your DSPy programs as MLflow models.
In this notebook, we will use DSPy with Llama-3.2-3B-Instruct, running locally via LMStudio. Note that you can swap in any other model running on an OpenAI-compatible endpoint. We will use the DSPy to build a system for summarizing research papers from arXiv at different levels of complexity.
Note that when setting up a local inference server with LMStudio you will likely need to increase the ctx_length parameter and set the overflow policy to truncate middle, ensuring the system prompt with the instructions is retained.
First, we will set up an MLflow experiment and enable DSPy autologging so we can easily view traces of all of our DSPy runs.
import dspy
import mlflow
from rich import print
from dotenv import load_dotenv
import os
load_dotenv()
mlflow.set_experiment("dspy-paper-summarization")
mlflow.dspy.autolog()
Next, we will configure the LLM we want to use. In this case, we will use Llama-3.2-3B-Instruct, running locally via LMStudio. Note that you can swap in any other model running on an OpenAI-compatible endpoint.
# Configure the LM with your local endpoint
lm_local = dspy.LM(
#"openai/lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF", # model name
"openai/unsloth/Llama-3.2-3B-Instruct-GGUF",
api_base="http://localhost:1234/v1", # local endpoint
api_key="whatever", # empty api_key for local endpoint
model_type='chat', # specify chat model type
cache=False # disable caching
)
lm_anthropic = dspy.LM(
"anthropic/claude-3-5-sonnet-20241022",
api_key=os.getenv("ANTHROPIC_API_KEY"),
)
lm_openai = dspy.LM(
"openai/gpt-4o-mini",
api_key=os.getenv("OPENAI_API_KEY"),
)
lm_gemini = dspy.LM(
"gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
)
lm_gemini_sm = dspy.LM(
"gemini/gemini-1.5-flash-8b",
api_key=os.getenv("GEMINI_API_KEY"),
)
# Set this as the default LM for DSPy
dspy.configure(lm=lm_gemini_sm)
# verify that the LLM is working
print(lm_gemini_sm("Please tell me what MLflow is for.")[0])
MLflow is an open-source platform for managing the entire machine learning lifecycle. This means it helps with: * **Experiment tracking:** Recording and comparing different experiments, including parameters, code versions, metrics, and artifacts. This allows you to easily reproduce and understand past experiments. * **Model registry:** Storing, sharing, and deploying machine learning models. It provides a central repository for models, allowing you to track their versions, metadata, and lineage. * **Projects:** Packaging and managing machine learning code, data, and configurations. This facilitates reproducibility and collaboration. * **Model deployment:** Deploying models to various platforms, including cloud services and on-premises environments. MLflow provides integrations with different deployment tools. In essence, MLflow helps you: * **Reproduce experiments:** Easily recreate past experiments with the same parameters and code. * **Manage models:** Track and deploy models efficiently. * **Collaborate:** Share experiments and models with others. * **Improve reproducibility:** Ensure that your machine learning work is repeatable and reliable. * **Scale your machine learning workflows:** Manage complex machine learning projects. MLflow is a powerful tool for anyone working with machine learning, from individual researchers to large teams.
We can already examine the traces captured via DSPy autologging:
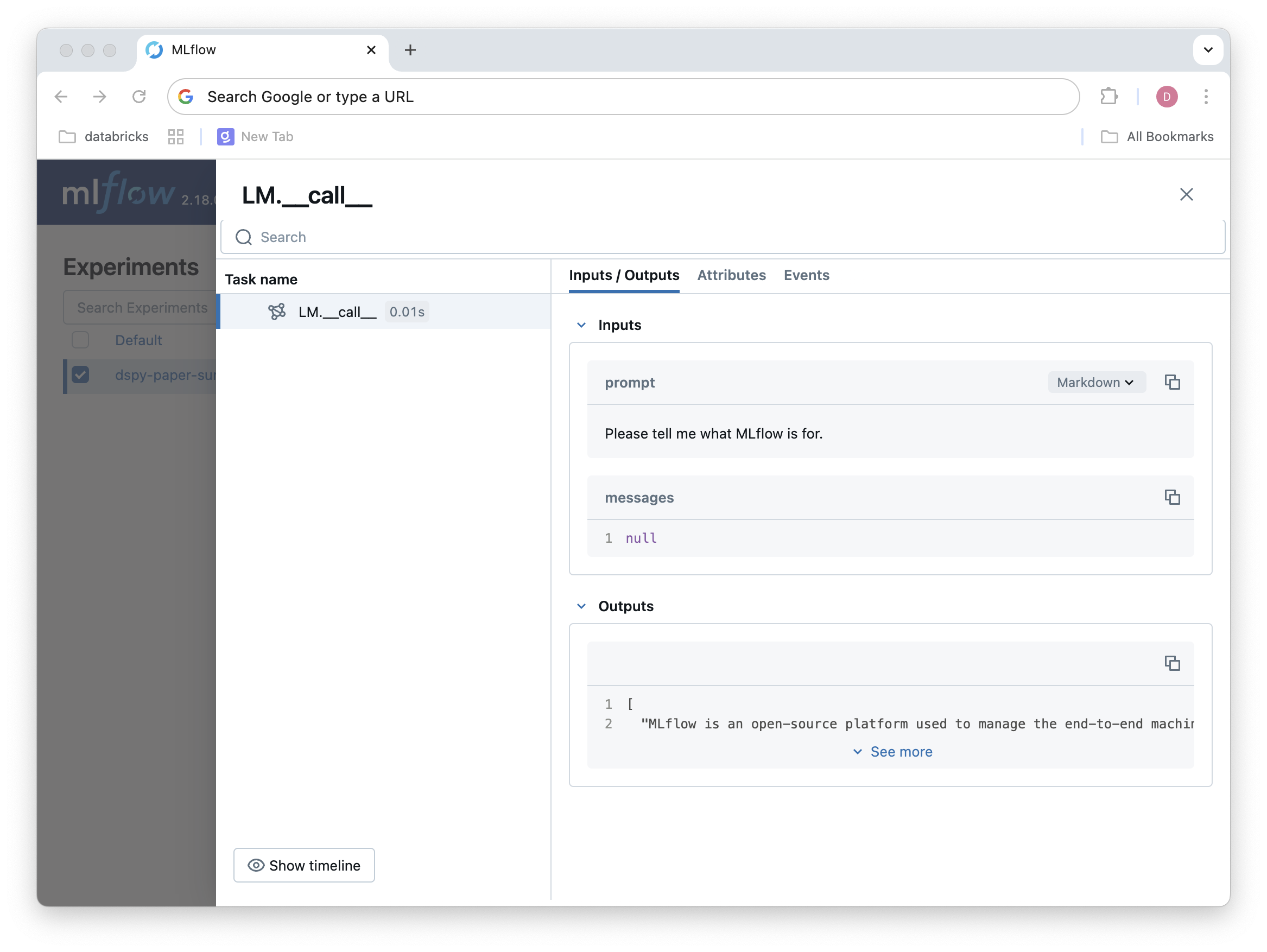
Now, to build our system, we need a few things:
A way to get the paper from an arxiv id
A way to specify the level of complexity of the summary we want
A way to evaluate the summary
Integrating these components will demonstrate how DSPy is Python: we don’t have to think in terms of prompts; we can write Python code for both the deterministic components (e.g. getting the paper) and the LLM-powered components (e.g. summarizing the paper).
For now, we will just focus on extracting and operating on the text from the paper, but this approach could be extended to look at images or other data modalities as well.
import arxiv
import PyPDF2
import io
import requests
def get_paper_from_arxiv(arxiv_id: str) -> tuple[str, str]:
"""
Download and extract text from an arxiv paper.
Args:
arxiv_id (str): The arxiv ID (e.g., '2311.12399' or 'arxiv:2311.12399')
Returns:
tuple[str, str]: (title, text) of the paper
"""
client = arxiv.Client()
# Clean the arxiv ID
arxiv_id = arxiv_id.replace('arxiv:', '').strip()
# Search for the paper
search = client.results(arxiv.Search(id_list=[arxiv_id]))
paper = next(search)
# Download the PDF
response = requests.get(paper.pdf_url)
pdf_file = io.BytesIO(response.content)
# Extract text from PDF
reader = PyPDF2.PdfReader(pdf_file)
text = ' '.join(page.extract_text() for page in reader.pages)
return paper.title, text
# get papers
paper_ids = ["2411.15138", "2411.15124", "2411.10442", "2411.10958", "2411.12372"]
papers = []
for paper_id in paper_ids:
papers.append(get_paper_from_arxiv(paper_id))
Set up the DSPy Signature#
A DSPy signature is a Python class that defines the inputs and outputs of a DSPy program. It is used to specify the structure of the data that will be passed into and out of the program.
A signature primarily consists of input fields (dspy.InputField) and output fields (dspy.OutputField). Input fields describe the data that will be passed into the program, while output fields describe the data that will be returned by the program. The class docstring also provides instructions or task descriptions.
We can also concisely define a signature as a string mapping inputs to outputs, such as ‘text: str -> sentiment: str’.
For our paper summarization task, we will define a signature that takes in a paper title, text, and complexity level, and outputs a summary at the specified complexity level.
from typing import Literal
class PaperSummarySignature(dspy.Signature):
"""Generate a summary of the provided research paper at a specified complexity level.
The summary can be up to four paragraphs long and should be tailored to the specified complexity level.
Complexity levels:
1: High school level - Use basic vocabulary and simple concepts. Avoid technical terms.
2: Early undergraduate - Introduce some basic technical terms with explanations
3: Advanced undergraduate - Use moderate technical language with occasional explanations
4: Graduate student - Use technical language freely with minimal explanations
5: Expert - Use sophisticated technical language and assume deep domain knowledge
"""
# Input fields
title: str = dspy.InputField(description="The title of the research paper")
complexity_level: Literal[1, 2, 3, 4, 5] = dspy.InputField(
description=(
"The desired complexity level of the generated summary, ranging from 1 (high school level) to 5 (graduate student level)"
)
)
text: str = dspy.InputField(description="The full text content of a single research paper")
# Output fields
summary: str = dspy.OutputField(description="A summary of the paper at the specified complexity level")
from typing import Literal
class WorsePaperSummarySignature(dspy.Signature):
"""Generate a summary of the provided research paper at a specified complexity level.
The summary can be up to four paragraphs long and should be tailored to the specified complexity level.
"""
# Input fields
title: str = dspy.InputField(description="The title of the research paper")
complexity_level: Literal[1, 2, 3, 4, 5] = dspy.InputField(
description=(
"The desired complexity level of the generated summary, ranging from 1 (more elementary) to 5 (more advanced)"
)
)
text: str = dspy.InputField(description="Text from a research paper")
# Output fields
summary: str = dspy.OutputField(description="A summary of the paper at the specified complexity level")
Set up the DSPy Module#
A DSPy module is a Python class inheriting from dspy.Module. A typical module has the following components:
an
__init__method that initializes the module with the necessary componentsa
forwardmethod that defines the core logic of the module
Signatures define the interface for a module, specifying the inputs and outputs. Signatures define the “contract” of inputs and outputs, while modules implement the actual logic of processing inputs into outputs using LLMs.
There are many built-in modules in DSPy implementing common LLM patterns, such as dspy.ChainOfThought and dspy.Predict. Read more here.
We will set up a simple module that wraps the dspy.ChainOfThought module to summarize a paper at a given complexity level.
class Summarize(dspy.Module):
def __init__(self):
# self.summarize = dspy.ChainOfThought(PaperSummarySignature)
self.summarize = dspy.Predict(PaperSummarySignature,
temperature=0.8)
def forward(self, title: str, text: str, complexity_level: int):
summary = self.summarize(
title=title,
text=text,
complexity_level=complexity_level
)
return summary
class SummarizeWorsePrompt(dspy.Module):
def __init__(self):
self.summarize = dspy.Predict(WorsePaperSummarySignature,
temperature=0.8)
def forward(self, title: str, text: str, complexity_level: int):
summary = self.summarize(
title=title,
text=text,
complexity_level=complexity_level
)
return summary
Test the Module#
program = SummarizeWorsePrompt()
paper = papers[0]
print(program(title=paper[0], text=paper[1][:50000], complexity_level=5)["summary"])
Material Anything is a fully automated diffusion framework for generating physically-based rendering (PBR) materials for any 3D object. Unlike previous methods that require complex pipelines or case-specific optimizations, this approach uses a pre-trained image diffusion model adapted for material estimation. A key innovation is the use of confidence masks within the diffusion model to handle various lighting conditions (realistic, unrealistic, and absence of lighting). The model progressively generates materials for different views of the object, ensuring consistency across views, and then refines these materials in UV space. This two-stage pipeline addresses the challenge of generating consistent and high-quality PBR materials, adaptable to a wide range of 3D objects and lighting conditions. Extensive experimentation demonstrates that Material Anything significantly outperforms existing methods, achieving state-of-the-art performance in generating accurate and realistic material maps for diverse object categories. The method utilizes a triple-head architecture and a rendering loss to enhance stability and material quality, effectively bridging the gap between natural images and material maps. The use of a confidence mask dynamically adjusts the model's focus based on the input object's lighting characteristics, optimizing the generation process for different scenarios. Finally, a UV-space refinement stage addresses potential inconsistencies and artifacts, further enhancing the generated material maps for practical applications.
print(program(title=paper[0], text=paper[1][:50000], complexity_level=1)["summary"])
Material Anything is a program that automatically creates realistic materials for 3D objects. It uses a pre-trained image diffusion model, which is a type of AI that creates images. This model is improved to work better with materials by adding a special "triple-head" design and a way to measure how well the materials look under different lighting. It also has a way to tell if the lighting in the image is realistic or not, so it can adjust how it creates the materials accordingly. The program works in two steps. First, it creates materials for each view of the object. It does this by using the pre-trained model and adjusting it to make material maps. To make sure the materials look good from different angles, it uses a special "confidence mask" that helps the program understand the lighting and how it affects the materials. Second, it takes the materials from each view and combines them into a single, consistent set of materials that work well together. It then uses a special part of the program to smooth out any problems that might happen when combining views. This program can handle many different types of objects and lighting situations, even ones without textures or where the lighting isn't realistic. It works much better than other methods that were used before. The results show that it creates high-quality materials that look very realistic.
There doesn’t seem to be a big difference between the two generated summaries in terms of complexity! We can use DSPy’s evaluation and optimization tools to help us improve the program without manually tweaking the prompts.
Evaluate#
Evaluation in DSPy is based on DSPy metrics. A metric is a function that scores the quality of a given output based on some criteria, typically in comparison with an example.
You can run metrics in a simple loop or in a more programmatic way using the dspy.evaluate module.
Metrics themselves can be DSPy modules, meaning they are also subject to iteration and improvement.
We want to evaluate our paper summaries to determine whether they are at the appropriate complexity level. To do so, we will use another DSPy program that will take a summary and determine whether it is at the correct complexity level. We will again follow the approach of first defining a signature, then defining a module that implements the logic of the metric.
class EvaluateSummary(dspy.Signature):
"""Given a summary of a research paper, rate its complexity level from 1 to 5.
The ratings correspond to the following levels of complexity:
1: Elementary - Suitable for general audience with no technical background
2: Basic - Suitable for undergraduate students or technical enthusiasts
3: Intermediate - Suitable for graduate students or industry practitioners
4: Advanced - Suitable for domain experts and researchers
5: Expert - Suitable for specialists in this specific research area
"""
summary: str = dspy.InputField(description="The summary of the research paper")
complexity_level: Literal[1, 2, 3, 4, 5] = dspy.OutputField(description="The complexity level of the summary")
class Metric(dspy.Module):
"""Given a summary and its complexity level, determine whether the summary is at the correct complexity level."""
def __init__(self, model=None):
# Allow passing in a specific model, or use the default configured one
if model:
with dspy.context(lm=model):
self.eval_complexity = dspy.ChainOfThought(EvaluateSummary)
else:
self.eval_complexity = dspy.ChainOfThought(EvaluateSummary)
def forward(self, example, pred, trace=None):
"""
Parameters:
- example: DSPy Example containing input fields and expected outputs
- pred: Prediction from the program containing generated fields
- trace: Used during bootstrapping to track optimization process
Returns:
- bool during bootstrapping (trace is not None)
- float (0-1) during normal evaluation
"""
# Get predicted complexity level for the generated summary
predicted = self.eval_complexity(summary=pred.summary).complexity_level
# Calculate raw score (0-5)
score = 5 - abs(predicted - example.complexity_level)
# Different behavior for bootstrapping vs evaluation
if trace is not None:
return score >= 4 # Only use high-quality examples for bootstrapping
return score / 5.0 # Normalize score for evaluation
Test the Metric#
# Create an example with the input data
example = dspy.Example(
title=paper[0],
text=paper[1],
complexity_level=1
).with_inputs("title", "text", "complexity_level")
pred = program(
title=example.title,
text=example.text,
complexity_level=example.complexity_level
)
metric_program = Metric(model=lm_openai)
score = metric_program(example, pred)
print(f"Metric score: {score}") # Will return a value between 0 and 1
Metric score: 0.6
Developing an Evaluation Dataset#
Now that we have a DSPy program and the means of evaluating it, we can develop a dataset of examples and scores and use them to iteratively improve the program.
To do so, we need to define dspy.Example objects, which contain the inputs and outputs of a program, as well as a score.
We will use five different papers and five different complexity levels to create a dataset of 25 examples. In a real-world scenario, you would want to use a larger and more diverse dataset to train your program.
from tqdm.notebook import tqdm
import random
mlflow.dspy.autolog()
# Create dataset of examples
dataset = []
total_iterations = len(papers) * 5 # 5 complexity levels per paper
with tqdm(total=total_iterations, desc="Generating summaries") as pbar:
for paper in papers:
title, text = paper
# Generate summary for each complexity level (1-5)
for complexity in range(1, 6):
result = program(
title=title,
text=text[:50000] + "... [truncated]", # truncate text to avoid token issues
complexity_level=complexity
)
# Create a DSPy Example object with the input fields
example = dspy.Example(
title=title,
text=text[:50000] + "... [truncated]",
complexity_level=complexity,
summary=result.summary
).with_inputs("title", "text", "complexity_level") # Specify which fields are inputs
dataset.append(example)
pbar.update(1)
Now that we have a dataset, we can conduct an evaluation run with DSPy.
from dspy.evaluate import Evaluate
# Set up the evaluator
evaluator = Evaluate(
devset=dataset,
metric=metric_program,
num_threads=4,
display_progress=True,
display_table=25
)
# Run the evaluation
print("Evaluating baseline program...")
results = evaluator(program)
Evaluating baseline program...
Average Metric: 19.40 / 25 (77.6%): 100%|██████████| 25/25 [00:06<00:00, 3.75it/s]
2024/12/06 11:08:33 INFO dspy.evaluate.evaluate: Average Metric: 19.4 / 25 (77.6%)
| title | text | complexity_level | example_summary | pred_summary | Metric | |
|---|---|---|---|---|---|---|
| 0 | Material Anything: Generating Materials for Any 3D Object via Diff... | Material Anything: Generating Materials for Any 3D Object via Diff... | 1 | Material Anything is a new way to automatically create realistic m... | Material Anything is a new way to automatically create realistic m... | ✔️ [0.600] |
| 1 | Material Anything: Generating Materials for Any 3D Object via Diff... | Material Anything: Generating Materials for Any 3D Object via Diff... | 2 | Material Anything is a new method for automatically generating phy... | Material Anything is a new method for automatically generating phy... | ✔️ [0.800] |
| 2 | Material Anything: Generating Materials for Any 3D Object via Diff... | Material Anything: Generating Materials for Any 3D Object via Diff... | 3 | Material Anything is a new, automated system for generating physic... | Material Anything is a new, automated system for generating physic... | ✔️ [1.000] |
| 3 | Material Anything: Generating Materials for Any 3D Object via Diff... | Material Anything: Generating Materials for Any 3D Object via Diff... | 4 | Material Anything is a fully automated framework for generating ph... | Material Anything is a fully automated framework for generating ph... | ✔️ [1.000] |
| 4 | Material Anything: Generating Materials for Any 3D Object via Diff... | Material Anything: Generating Materials for Any 3D Object via Diff... | 5 | Material Anything is a fully automated diffusion framework for gen... | Material Anything is a fully automated diffusion framework for gen... | ✔️ [0.800] |
| 5 | TÜLU 3: Pushing Frontiers in Open Language Model Post-Training | TÜLU3: Pushing Frontiers in Open Language Model Post-Training Nath... | 1 | This research paper introduces TÜLU3, a family of open-source, sta... | This research paper introduces TÜLU3, a family of open-source, sta... | ✔️ [0.600] |
| 6 | TÜLU 3: Pushing Frontiers in Open Language Model Post-Training | TÜLU3: Pushing Frontiers in Open Language Model Post-Training Nath... | 2 | TÜLU3 is a new family of open-source, state-of-the-art language mo... | TÜLU3 is a new family of open-source, state-of-the-art language mo... | ✔️ [0.600] |
| 7 | TÜLU 3: Pushing Frontiers in Open Language Model Post-Training | TÜLU3: Pushing Frontiers in Open Language Model Post-Training Nath... | 3 | TÜLU3 is a family of open-source, state-of-the-art language models... | TÜLU3 is a family of open-source, state-of-the-art language models... | ✔️ [0.800] |
| 8 | TÜLU 3: Pushing Frontiers in Open Language Model Post-Training | TÜLU3: Pushing Frontiers in Open Language Model Post-Training Nath... | 4 | TÜLU3 is a family of state-of-the-art, open-source language models... | TÜLU3 is a family of state-of-the-art, open-source language models... | ✔️ [1.000] |
| 9 | TÜLU 3: Pushing Frontiers in Open Language Model Post-Training | TÜLU3: Pushing Frontiers in Open Language Model Post-Training Nath... | 5 | TÜLU3 is a family of open-source, state-of-the-art language models... | TÜLU3 is a family of open-source, state-of-the-art language models... | ✔️ [0.800] |
| 10 | Enhancing the Reasoning Ability of Multimodal Large Language Model... | Enhancing the Reasoning Ability of Multimodal Large Language Model... | 1 | This research paper introduces a method called Mixed Preference Op... | This research paper introduces a method called Mixed Preference Op... | ✔️ [0.400] |
| 11 | Enhancing the Reasoning Ability of Multimodal Large Language Model... | Enhancing the Reasoning Ability of Multimodal Large Language Model... | 2 | This research paper introduces a method called Mixed Preference Op... | This research paper introduces a method called Mixed Preference Op... | ✔️ [0.800] |
| 12 | Enhancing the Reasoning Ability of Multimodal Large Language Model... | Enhancing the Reasoning Ability of Multimodal Large Language Model... | 3 | This research paper introduces a method called Mixed Preference Op... | This research paper introduces a method called Mixed Preference Op... | ✔️ [1.000] |
| 13 | Enhancing the Reasoning Ability of Multimodal Large Language Model... | Enhancing the Reasoning Ability of Multimodal Large Language Model... | 4 | This paper introduces a method called Mixed Preference Optimizatio... | This paper introduces a method called Mixed Preference Optimizatio... | ✔️ [1.000] |
| 14 | Enhancing the Reasoning Ability of Multimodal Large Language Model... | Enhancing the Reasoning Ability of Multimodal Large Language Model... | 5 | This research paper presents a novel approach, Mixed Preference Op... | This research paper presents a novel approach, Mixed Preference Op... | ✔️ [0.800] |
| 15 | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | 1 | This research paper introduces SageAttention2, a method for accele... | This research paper introduces SageAttention2, a method for accele... | ✔️ [0.400] |
| 16 | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | 2 | This research paper, "SageAttention2 Technical Report: Accurate 4 ... | This research paper, "SageAttention2 Technical Report: Accurate 4 ... | ✔️ [0.600] |
| 17 | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | 3 | This paper, "SageAttention2 Technical Report," presents SageAttent... | This paper, "SageAttention2 Technical Report," presents SageAttent... | ✔️ [0.800] |
| 18 | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | 4 | This research paper, "SageAttention2 Technical Report: Accurate 4 ... | This research paper, "SageAttention2 Technical Report: Accurate 4 ... | ✔️ [1.000] |
| 19 | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug... | 5 | This paper, "SageAttention2 Technical Report: Accurate 4 Bit Atten... | This paper, "SageAttention2 Technical Report: Accurate 4 Bit Atten... | ✔️ [0.800] |
| 20 | RedPajama: an Open Dataset for Training Large Language Models | RedPajama: an Open Dataset for Training Large Language Models Maur... | 1 | This paper introduces the RedPajama datasets, a large and open-sou... | This paper introduces the RedPajama datasets, a large and open-sou... | ✔️ [0.600] |
| 21 | RedPajama: an Open Dataset for Training Large Language Models | RedPajama: an Open Dataset for Training Large Language Models Maur... | 2 | This paper introduces the RedPajama datasets, a large and open-sou... | This paper introduces the RedPajama datasets, a large and open-sou... | ✔️ [0.800] |
| 22 | RedPajama: an Open Dataset for Training Large Language Models | RedPajama: an Open Dataset for Training Large Language Models Maur... | 3 | The paper introduces the RedPajama datasets, a large-scale, open-s... | The paper introduces the RedPajama datasets, a large-scale, open-s... | ✔️ [1.000] |
| 23 | RedPajama: an Open Dataset for Training Large Language Models | RedPajama: an Open Dataset for Training Large Language Models Maur... | 4 | The paper introduces the RedPajama datasets, a significant contrib... | The paper introduces the RedPajama datasets, a significant contrib... | ✔️ [0.800] |
| 24 | RedPajama: an Open Dataset for Training Large Language Models | RedPajama: an Open Dataset for Training Large Language Models Maur... | 5 | The paper presents the RedPajama datasets, a significant contribut... | The paper presents the RedPajama datasets, a significant contribut... | ✔️ [0.600] |
Optimize program#
from dspy.teleprompt import MIPROv2
optim = MIPROv2(
metric = metric_program,
prompt_model=lm_openai,
task_model=lm_openai,
auto="light"
)
# Optimize program
print("Optimizing program with MIPRO...")
optimized_program = optim.compile(
program.deepcopy(),
trainset=dataset,#_with_metrics,
max_bootstrapped_demos=3,
max_labeled_demos=4,
requires_permission_to_run=False,
)
# Save optimize program for future use
optimized_program.save("mipro_optimized")
Optimizing program with MIPRO...
2024/12/06 11:09:23 INFO dspy.teleprompt.mipro_optimizer_v2:
RUNNING WITH THE FOLLOWING LIGHT AUTO RUN SETTINGS:
num_trials: 7
minibatch: False
num_candidates: 5
valset size: 20
2024/12/06 11:09:23 INFO dspy.teleprompt.mipro_optimizer_v2:
==> STEP 1: BOOTSTRAP FEWSHOT EXAMPLES <==
2024/12/06 11:09:23 INFO dspy.teleprompt.mipro_optimizer_v2: These will be used as few-shot example candidates for our program and for creating instructions.
2024/12/06 11:09:23 INFO dspy.teleprompt.mipro_optimizer_v2: Bootstrapping N=5 sets of demonstrations...
Bootstrapping set 1/5
Bootstrapping set 2/5
Bootstrapping set 3/5
60%|██████ | 3/5 [00:15<00:10, 5.33s/it]
Bootstrapped 3 full traces after 3 examples for up to 1 rounds, amounting to 3 attempts.
Bootstrapping set 4/5
20%|██ | 1/5 [00:05<00:20, 5.25s/it]
Bootstrapped 1 full traces after 1 examples for up to 1 rounds, amounting to 1 attempts.
Bootstrapping set 5/5
60%|██████ | 3/5 [00:37<00:25, 12.57s/it]
2024/12/06 11:10:22 INFO dspy.teleprompt.mipro_optimizer_v2:
==> STEP 2: PROPOSE INSTRUCTION CANDIDATES <==
2024/12/06 11:10:22 INFO dspy.teleprompt.mipro_optimizer_v2: We will use the few-shot examples from the previous step, a generated dataset summary, a summary of the program code, and a randomly selected prompting tip to propose instructions.
Bootstrapped 3 full traces after 3 examples for up to 1 rounds, amounting to 3 attempts.
2024/12/06 11:10:35 INFO dspy.teleprompt.mipro_optimizer_v2:
Proposing instructions...
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: Proposed Instructions for Predictor 0:
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: 0: Generate a summary of the provided research paper at a specified complexity level.
The summary can be up to four paragraphs long and should be tailored to the specified complexity level.
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: 1: Generate a tailored summary of the provided research paper based on the specified complexity level (1-5). The summary should be no longer than four paragraphs and should be suited to the understanding of the intended audience.
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: 2: Create a detailed summary of the research paper titled "Material Anything: Generating Materials for Any 3D Object via Diffusion." The summary should be structured into up to four paragraphs and tailored to a complexity level of 3, providing a clear understanding of the program's methodology, innovations, and applications. Highlight key features such as the use of diffusion models, the role of confidence masks in material estimation, and the significance of the Material3D dataset in training the model. Ensure that the summary captures both the technical aspects and the broader implications of the research for 3D content creation.
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: 3: You are a research assistant tasked with simplifying complex academic content. Generate a summary of the provided research paper at a specified complexity level. The summary can be up to four paragraphs long and should be tailored to the specified complexity level, ranging from 1 (more elementary) to 5 (more advanced). Ensure that the essential information is preserved while making it accessible for the target audience.
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: 4: Create a concise summary of the research paper titled "Material Anything: Generating Materials for Any 3D Object via Diffusion." Tailor the summary to a complexity level of 3, ensuring it captures the key innovations, methodologies, and results discussed in the paper. The summary should highlight the unique aspects of the triple-head architecture, the use of confidence masks, and the progressive material generation strategy, while being accessible to readers with a moderate understanding of the topic. Limit the summary to four paragraphs.
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2:
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: Evaluating the default program...
Average Metric: 15.20 / 20 (76.0%): 100%|██████████| 20/20 [00:00<00:00, 3441.90it/s]
2024/12/06 11:11:25 INFO dspy.evaluate.evaluate: Average Metric: 15.200000000000001 / 20 (76.0%)
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: Default program score: 76.0
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: ==> STEP 3: FINDING OPTIMAL PROMPT PARAMETERS <==
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: We will evaluate the program over a series of trials with different combinations of instructions and few-shot examples to find the optimal combination using Bayesian Optimization.
/Users/daniel.liden/git/devrel-examples/.venv/lib/python3.13/site-packages/optuna/_experimental.py:31: ExperimentalWarning: Argument ``multivariate`` is an experimental feature. The interface can change in the future.
warnings.warn(
2024/12/06 11:11:25 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 1 / 7 =====
Average Metric: 16.20 / 20 (81.0%): 100%|██████████| 20/20 [01:12<00:00, 3.64s/it]
2024/12/06 11:12:38 INFO dspy.evaluate.evaluate: Average Metric: 16.2 / 20 (81.0%)
2024/12/06 11:12:38 INFO dspy.teleprompt.mipro_optimizer_v2: Best full score so far! Score: 81.0
2024/12/06 11:12:38 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 81.0 with parameters ['Predictor 0: Instruction 1', 'Predictor 0: Few-Shot Set 1'].
2024/12/06 11:12:38 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [76.0, 81.0]
2024/12/06 11:12:38 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 81.0
2024/12/06 11:12:38 INFO dspy.teleprompt.mipro_optimizer_v2: =======================
2024/12/06 11:12:38 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 2 / 7 =====
Average Metric: 16.20 / 20 (81.0%): 100%|██████████| 20/20 [01:09<00:00, 3.49s/it]
2024/12/06 11:13:48 INFO dspy.evaluate.evaluate: Average Metric: 16.2 / 20 (81.0%)
2024/12/06 11:13:48 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 81.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 1'].
2024/12/06 11:13:48 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [76.0, 81.0, 81.0]
2024/12/06 11:13:48 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 81.0
2024/12/06 11:13:48 INFO dspy.teleprompt.mipro_optimizer_v2: =======================
2024/12/06 11:13:48 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 3 / 7 =====
Average Metric: 16.20 / 20 (81.0%): 100%|██████████| 20/20 [01:05<00:00, 3.25s/it]
2024/12/06 11:14:53 INFO dspy.evaluate.evaluate: Average Metric: 16.2 / 20 (81.0%)
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 81.0 with parameters ['Predictor 0: Instruction 4', 'Predictor 0: Few-Shot Set 1'].
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [76.0, 81.0, 81.0, 81.0]
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 81.0
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: =======================
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 4 / 7 =====
Average Metric: 16.20 / 20 (81.0%): 100%|██████████| 20/20 [00:00<00:00, 3612.66it/s]
2024/12/06 11:14:53 INFO dspy.evaluate.evaluate: Average Metric: 16.2 / 20 (81.0%)
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 81.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 1'].
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [76.0, 81.0, 81.0, 81.0, 81.0]
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 81.0
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: =======================
2024/12/06 11:14:53 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 5 / 7 =====
Average Metric: 15.00 / 20 (75.0%): 100%|██████████| 20/20 [01:07<00:00, 3.36s/it]
2024/12/06 11:16:00 INFO dspy.evaluate.evaluate: Average Metric: 15.0 / 20 (75.0%)
2024/12/06 11:16:00 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 75.0 with parameters ['Predictor 0: Instruction 4', 'Predictor 0: Few-Shot Set 3'].
2024/12/06 11:16:00 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [76.0, 81.0, 81.0, 81.0, 81.0, 75.0]
2024/12/06 11:16:00 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 81.0
2024/12/06 11:16:00 INFO dspy.teleprompt.mipro_optimizer_v2: =======================
2024/12/06 11:16:00 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 6 / 7 =====
Average Metric: 16.20 / 20 (81.0%): 100%|██████████| 20/20 [01:00<00:00, 3.02s/it]
2024/12/06 11:17:01 INFO dspy.evaluate.evaluate: Average Metric: 16.2 / 20 (81.0%)
2024/12/06 11:17:01 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 81.0 with parameters ['Predictor 0: Instruction 0', 'Predictor 0: Few-Shot Set 1'].
2024/12/06 11:17:01 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [76.0, 81.0, 81.0, 81.0, 81.0, 75.0, 81.0]
2024/12/06 11:17:01 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 81.0
2024/12/06 11:17:01 INFO dspy.teleprompt.mipro_optimizer_v2: =======================
2024/12/06 11:17:01 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 7 / 7 =====
Average Metric: 15.60 / 20 (78.0%): 100%|██████████| 20/20 [01:21<00:00, 4.06s/it]
2024/12/06 11:18:22 INFO dspy.evaluate.evaluate: Average Metric: 15.6 / 20 (78.0%)
2024/12/06 11:18:22 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 78.0 with parameters ['Predictor 0: Instruction 4', 'Predictor 0: Few-Shot Set 4'].
2024/12/06 11:18:22 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [76.0, 81.0, 81.0, 81.0, 81.0, 75.0, 81.0, 78.0]
2024/12/06 11:18:22 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 81.0
2024/12/06 11:18:22 INFO dspy.teleprompt.mipro_optimizer_v2: =======================
2024/12/06 11:18:22 INFO dspy.teleprompt.mipro_optimizer_v2: Returning best identified program with score 81.0!
print("original: ",program(title=paper[0], text=paper[1][:50000], complexity_level=1)["summary"],
"\n\n\noptimized: ",optimized_program(title=paper[0], text=paper[1][:50000], complexity_level=1)["summary"])
original: This paper introduces the RedPajama datasets, a large and open-source collection of text data for training large language models (LLMs). RedPajama-V1 is a replication of the LLaMA training dataset, while RedPajama-V2 is a massive web-only dataset containing raw, unfiltered text along with quality signals. The datasets are designed with transparency, scale, and versatility in mind, providing a valuable resource for the LLM community. Quality signals in RedPajama-V2 allow users to filter the data to create subsets of varying quality, which are then evaluated using various NLP benchmarks. Experiments with decoder-only Transformer models show that filtering with the quality signals can improve model performance. The authors believe that these datasets will contribute to the development of more transparent and high-performing LLMs. optimized: RedPajama is a large dataset of text that can be used to train powerful language models. It's important because many of the best language models don't share details about how their training data was created. RedPajama is different because it's open source, meaning anyone can use it and see how it was made. The dataset comes in two versions. The first is a copy of the data used to train another popular language model, LLaMA. The second is a much larger collection of text pulled from the internet, along with information about the quality of each piece of text. This quality information helps researchers figure out which parts of the dataset are better to use for training, so they can build even more accurate language models.
print("original: ",program(title=paper[0], text=paper[1][:50000], complexity_level=5)["summary"],
"\n\n\noptimized: ",optimized_program(title=paper[0], text=paper[1][:50000], complexity_level=5)["summary"])
original: The paper introduces RedPajama, a large, open-source dataset for training large language models (LLMs). It addresses three crucial challenges: transparency in model development, access to high-quality data, and availability of artifacts and metadata. RedPajama-V1 is an open-source reproduction of the LLaMA training dataset, while RedPajama-V2 is a massive web-only dataset comprised of raw, unfiltered text data along with quality signals and metadata, spanning over 100 trillion tokens across multiple domains. This allows researchers and developers to create their own filtered subsets, promoting transparency and versatility. The paper details the creation process, data processing steps, and quality signals for both datasets, including the reproduction of the LLaMA training data from seven sources (CommonCrawl, C4, GitHub, etc.) and the significant curation effort involved in RedPajama-V2 from CommonCrawl data. Extensive ablation studies with decoder-only Transformer models demonstrate the effectiveness of the quality signals in creating high-performing models on various NLP benchmarks. The paper concludes by emphasizing the importance of open-source datasets and highlighting RedPajama's potential to advance the development of transparent and high-performing LLMs at scale, while also acknowledging limitations of the study. optimized: RedPajama is a large, open-source dataset for training large language models (LLMs). It's significant because it aims for transparency in dataset creation, providing detailed information about how the data was collected and processed, unlike many other leading LLMs. The dataset has two main versions: RedPajama-V1, a reproduction of the LLaMA training dataset, and RedPajama-V2, a massive web-only dataset containing over 100 trillion tokens from various languages, spanning the years 2014-2023. Crucially, RedPajama-V2 includes a variety of "quality signals" (e.g., measures of natural language, repetitiveness, and content quality) with each document. This allows researchers to create customized subsets of the data based on specific quality criteria, leading to LLMs with varying performance on different benchmarks. The paper also details the challenges of training large language models on this scale, including adapting to specialized hardware (like the Summit supercomputer) and using techniques to maintain model stability. The results show that even with a significant size advantage, RedPajama-V2 can perform comparably or better than other leading open-source LLMs trained on smaller, more meticulously curated datasets. The dataset and its associated quality signals are intended to enable further research into creating high-quality LLM training data from web sources.
Log the model to MLflow#
with mlflow.start_run():
model_info = mlflow.dspy.log_model(
optimized_program,
"optim_model",
input_example={"title": "dummy_title", "text": "dummy_text", "complexity_level": 1},
)
/Users/daniel.liden/git/devrel-examples/.venv/lib/python3.13/site-packages/mlflow/types/utils.py:407: UserWarning: Hint: Inferred schema contains integer column(s). Integer columns in Python cannot represent missing values. If your input data contains missing values at inference time, it will be encoded as floats and will cause a schema enforcement error. The best way to avoid this problem is to infer the model schema based on a realistic data sample (training dataset) that includes missing values. Alternatively, you can declare integer columns as doubles (float64) whenever these columns may have missing values. See `Handling Integers With Missing Values <https://www.mlflow.org/docs/latest/models.html#handling-integers-with-missing-values>`_ for more details.
warnings.warn(
2024/12/06 11:22:30 WARNING mlflow.models.signature: Failed to infer the model signature from the input example. Reason: MlflowException("Dspy model doesn't support multiple inputs or batch inference. Please provide a single input."). To see the full traceback, set the logging level to DEBUG via `logging.getLogger("mlflow").setLevel(logging.DEBUG)`. To disable automatic signature inference, set `signature` to `False` in your `log_model` or `save_model` call.
2024/12/06 11:22:33 WARNING mlflow.utils.environment: Failed to resolve installed pip version. ``pip`` will be added to conda.yaml environment spec without a version specifier.
loaded_model = mlflow.dspy.load_model(model_info.model_uri)
print(loaded_model(title=paper[0], text=paper[1][:50000], complexity_level=1)["summary"])
RedPajama is a large dataset of text that can be used to train powerful language models. It's important because many of the best language models don't share details about how their training data was created. RedPajama is different because it's open source, meaning anyone can use it and see how it was made. The dataset comes in two versions. The first is a copy of the data used to train another popular language model, LLaMA. The second is a much larger collection of text pulled from the internet, along with information about the quality of each piece of text. This quality information helps researchers figure out which parts of the dataset are better to use for training, so they can build even more accurate language models.