Using the MLflow Prompt Engineering UI#
This notebook will show how to use the MLflow Prompt Engineering UI with the Databricks Foundation Model API. The prompt engineering UI lets you combine different models, prompts, and parameter configurations and works seamlessly with the Foundation Model API in Databricks.
Getting Started#
Navigate to the MLflow Experiment UI#
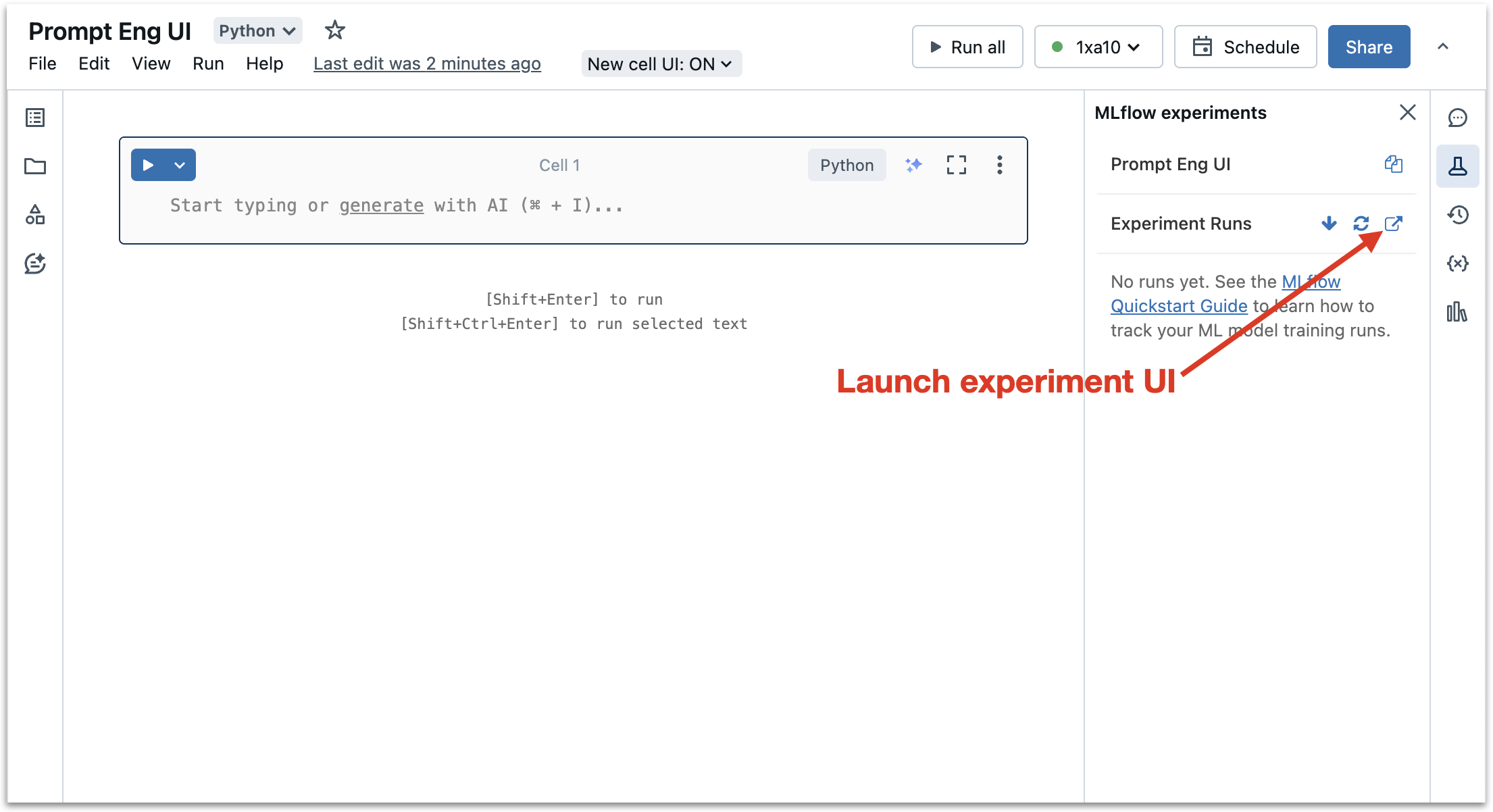
First, assuming you are starting from a Databricks Notebook environment, launch the MLflow Experiment UI. Click the “MLflow Experiments” icon and then click the “View Experiment UI” button, as shown in the following screenshot.
Start a New MLflow Run using Prompt Engineering#
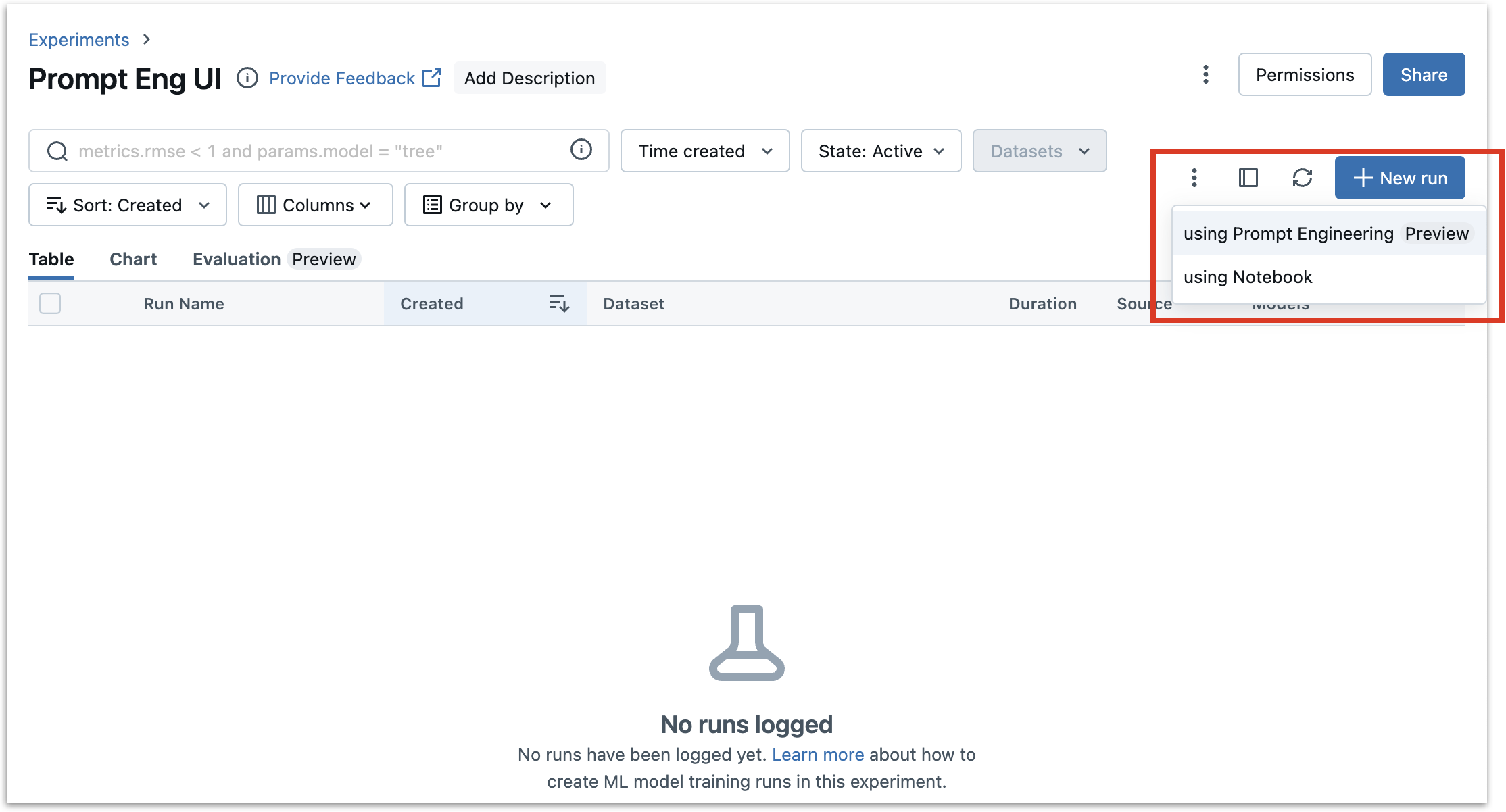
Next, click “+New Run” and select “using Prompt Engineering” as shown in the image below.
Select a Foundation Model API Model#
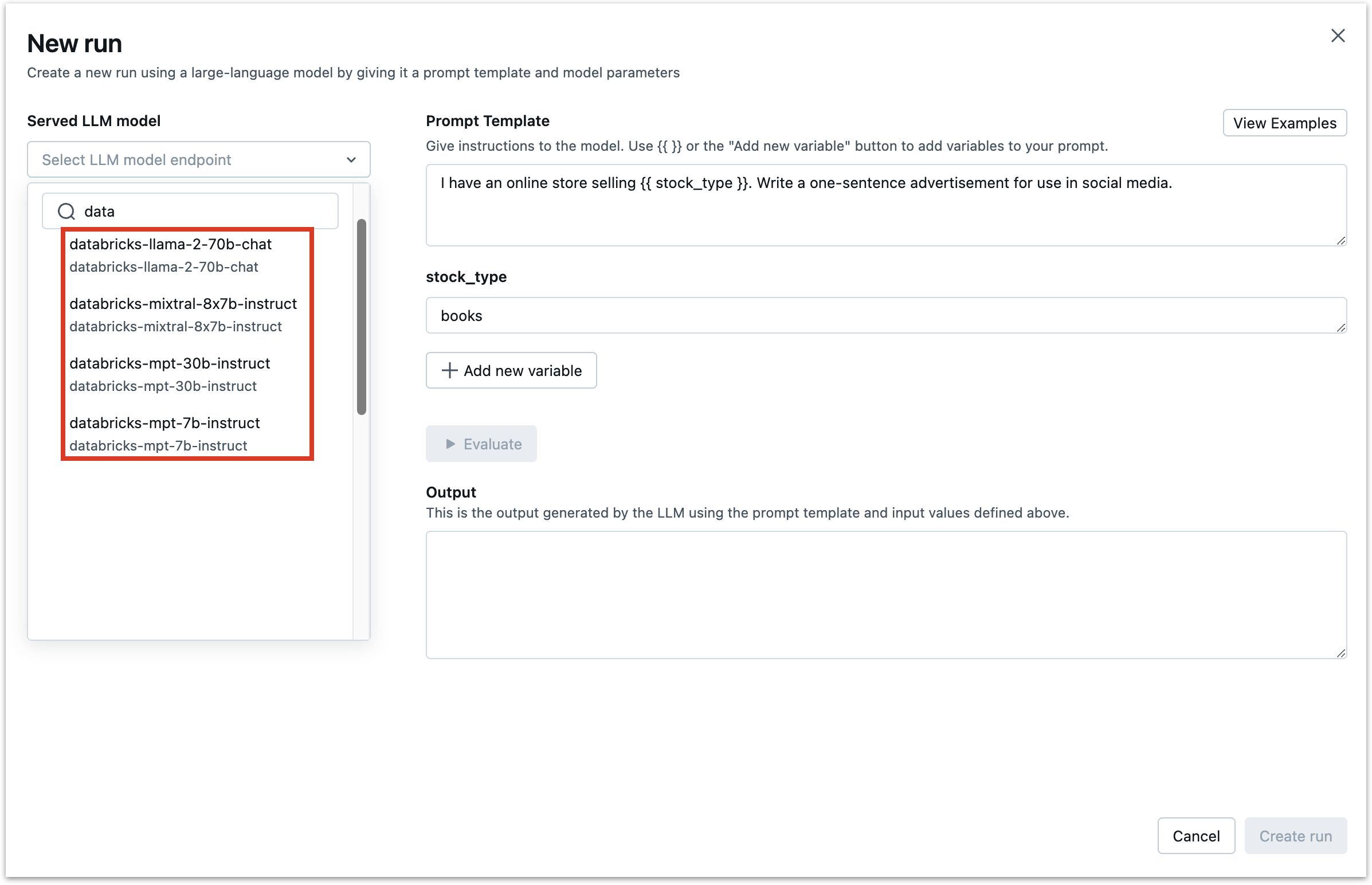
Models from the foundation model API start with databricks-. Select a model from the “Served LLM Model” dropdown.
Fill Out the Prompt Template#
The Prompt Engineering UI allows you to compare the performance of different prompts and different models using a the same prompt template. In the example below, we simulate a RAG scenario and provide a source text about Delta Lake. We then configure a variable called “question”, formatted {{ question }}, where user prompts will be inserted. We can see how different prompts and models operate with this same template.
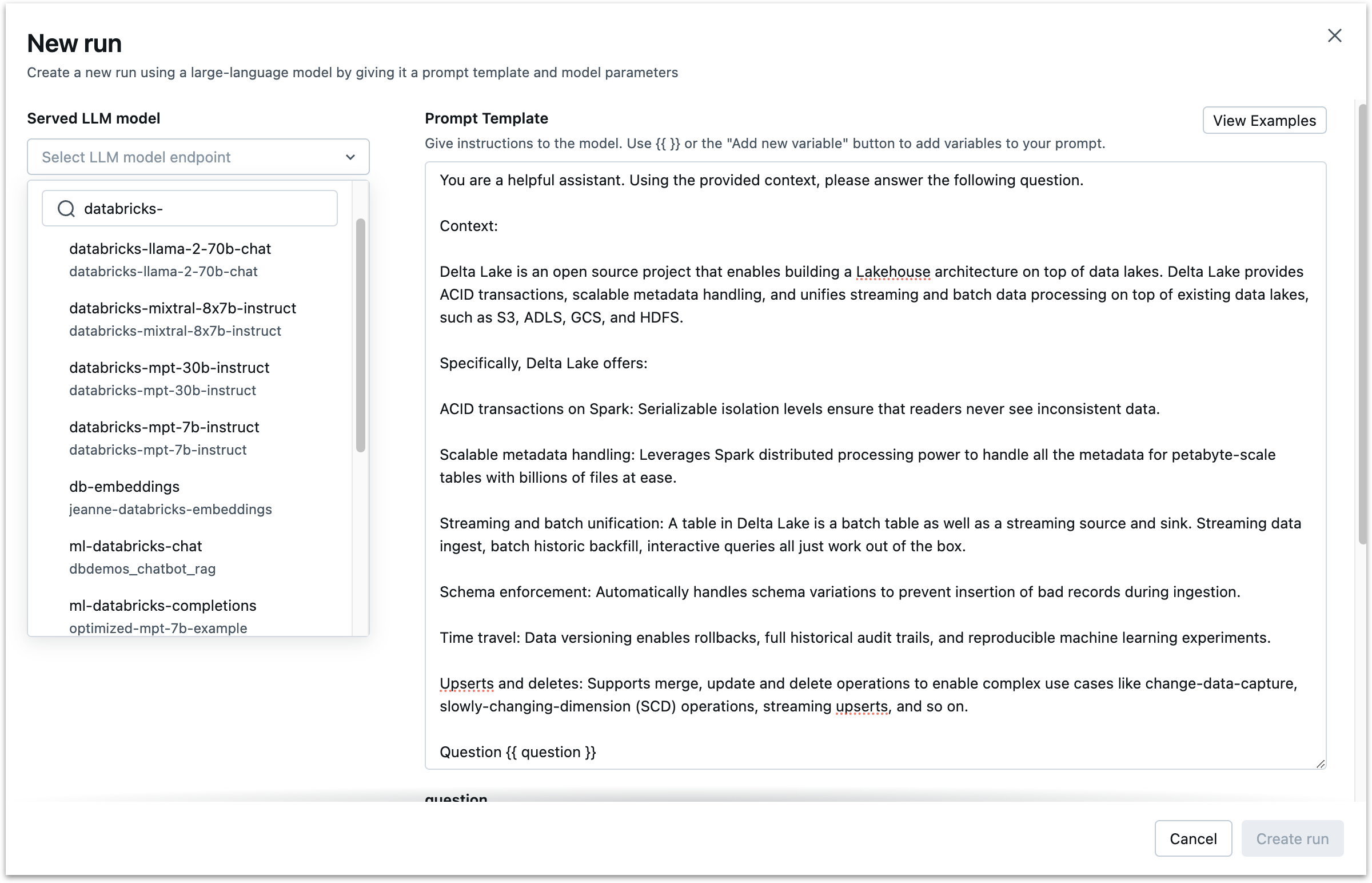
Note that, at this phase, you can also configure some model generation parameters, specifically “temperature,” “Max tokens,” and “Stop Sequences.”
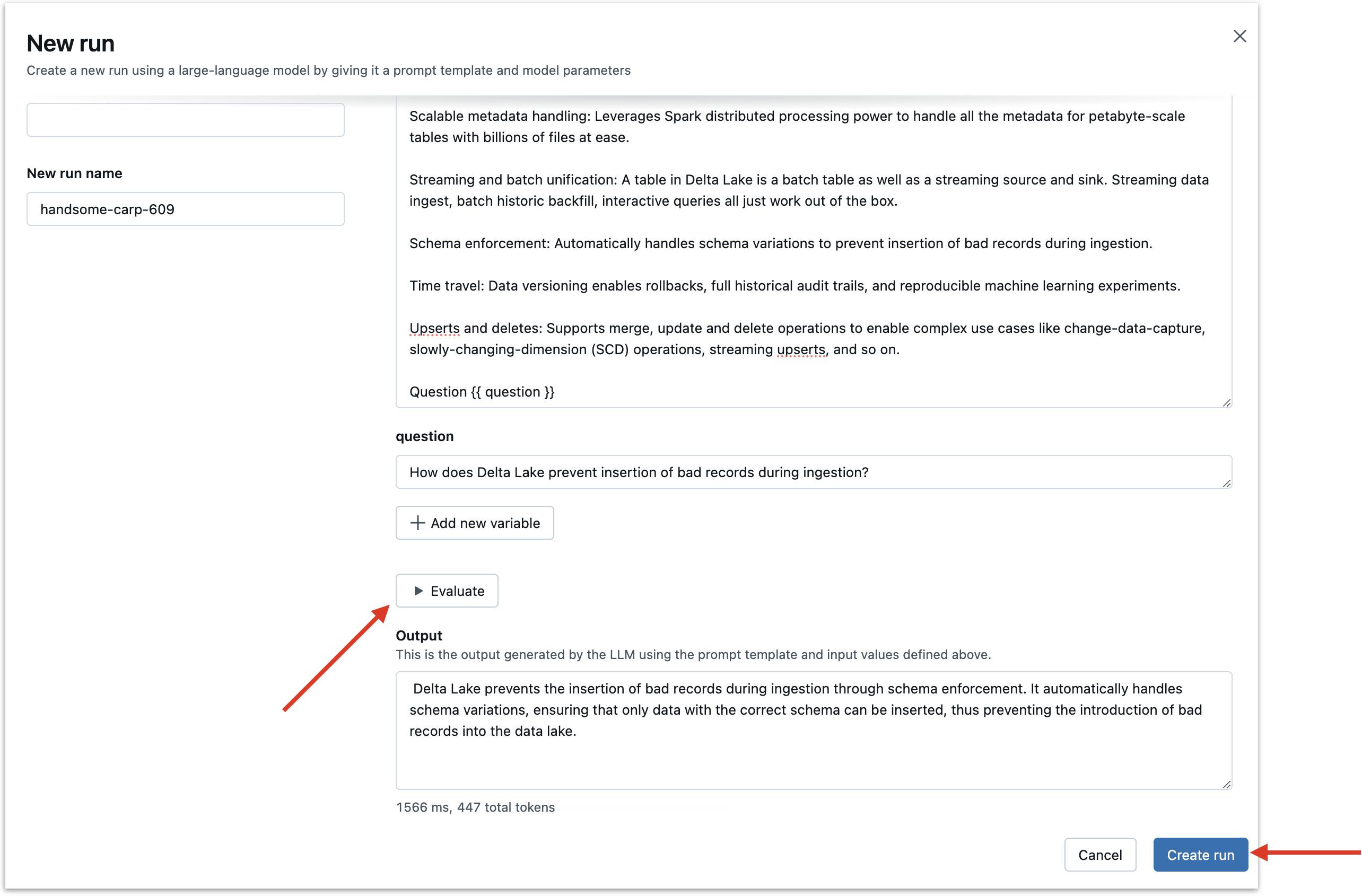
Create the first Run#
After filling out the prompt template, fill out an initial question, click “Evaluate”, and then click “Create run” at the bottom.
Adding new prompts and new runs#
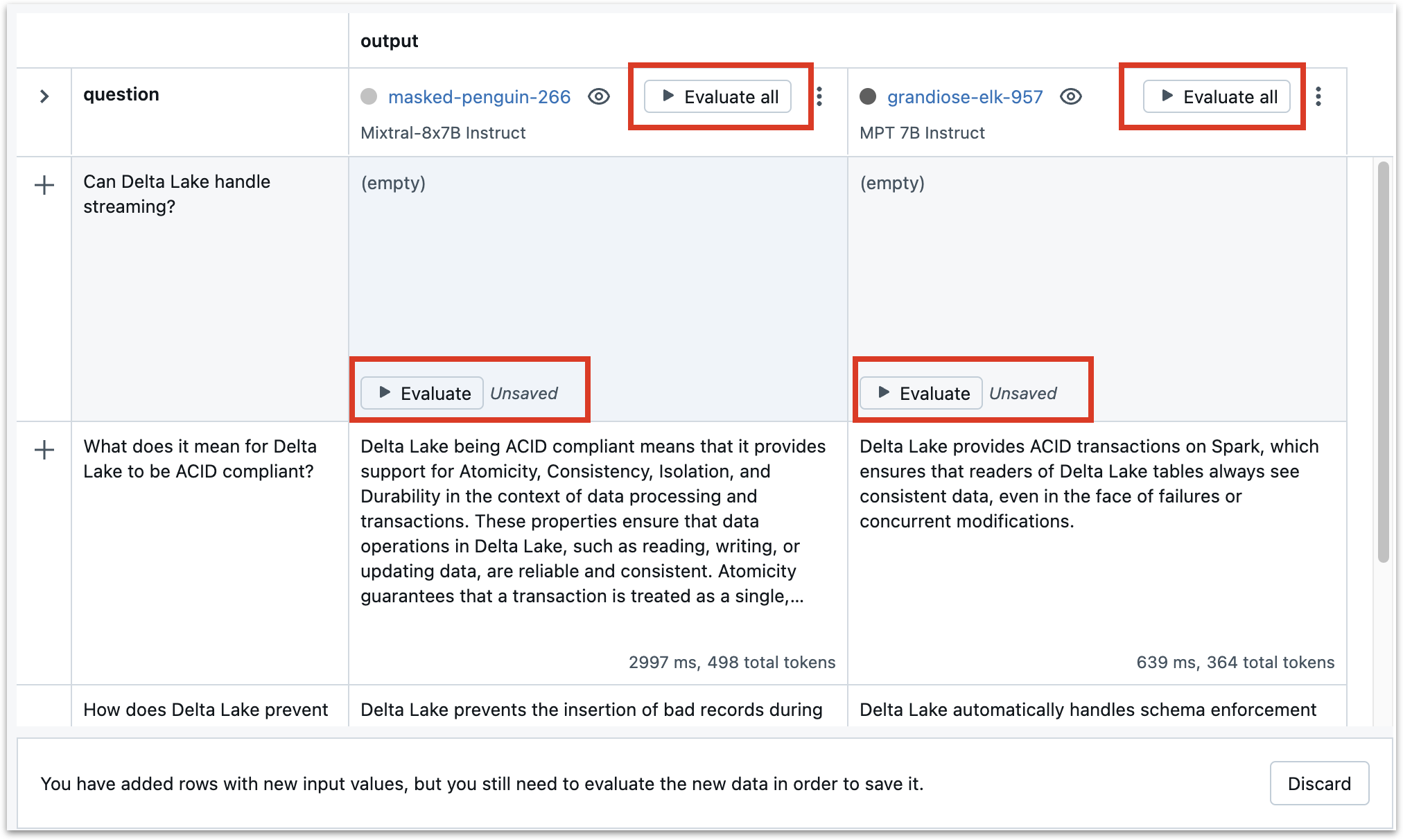
At this point, you can see a table with one row (for the initial question) and one column (for the initial model). You can add new questions, which will be inserted into the same template, and new models, which you can evaluate on the same questions.
To add a new question, click the “+” button on the left side of the table and enter the question.
To add a new model, click the “+ New run” button on the upper right side of the interface and repeat the process above for the new model. You can also use the new run interface to configure different templates and variables.
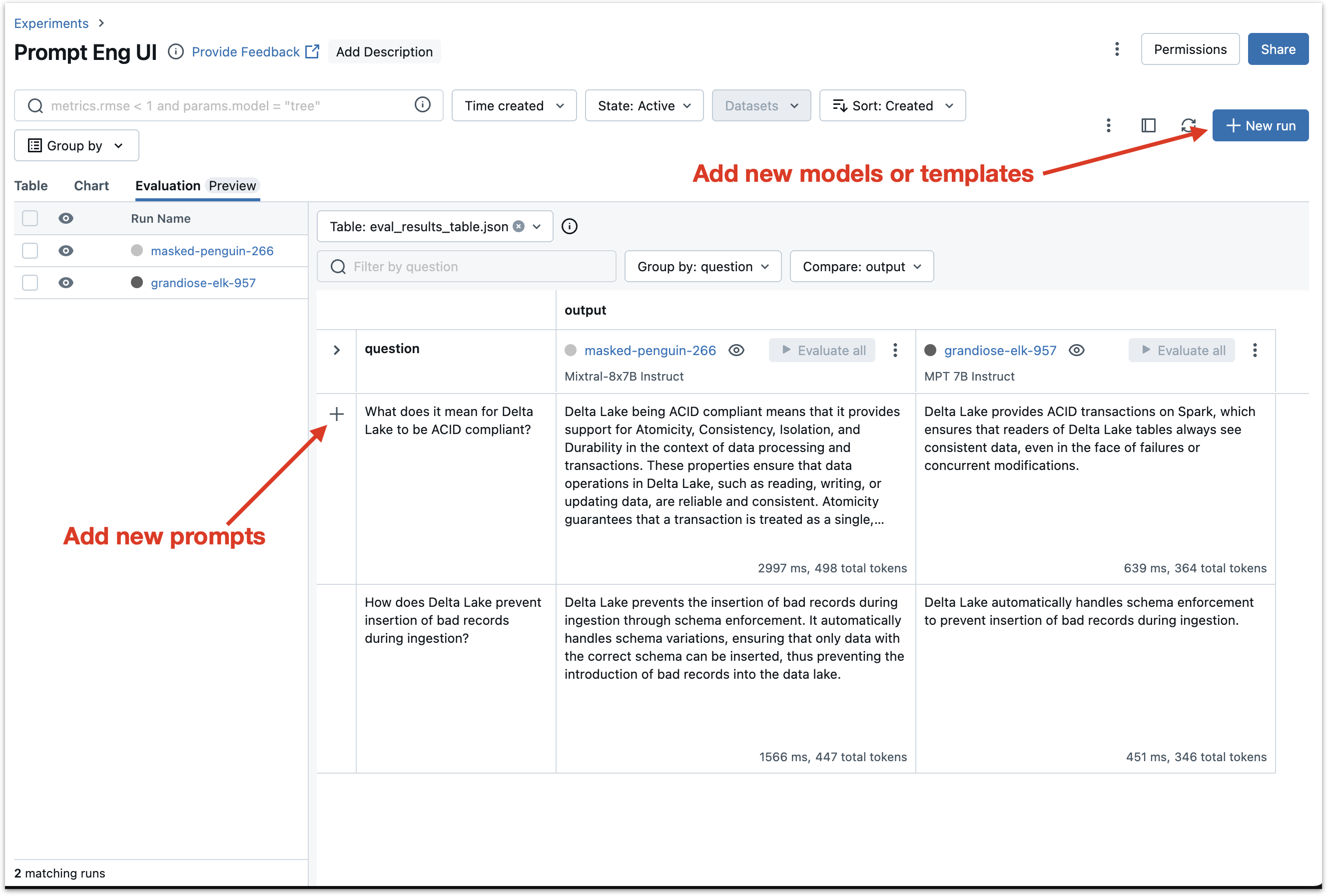
Evaluating cells after adding new prompts or models#
Adding new prompts or models does not automatically evaluate all combinations of models and prompts. To evaluate after adding new models/prompts, click the “Evaluate” button in empty cells or “Evaluate all” in the column (run) headers.